
こんにちは、プラットフォーム開発部のtoshと申します。 この記事は、 みらい翻訳のカレンダー | Advent Calendar 2023 - Qiita の5日目です。
はじめに
AWSでシステムを構築する場合、ログをCloudWatch Logsに集約することが多いと思います。
CloudWatch Logsにログを保存するのは費用が発生するため、CloudWatch Logsの保持期間を短く設定しつつS3に転送するパターンは一般的かと思います。
また、エラーログはS3に転送するだけではなく、Slackなどに通知することも多いと思います。
今回は、すでにCloudWatch Logsに保存されているログをS3に転送しつつ、Slackに通知する方法をご紹介します。
なお、今回はCloudWatch LogsやS3、terraformについての基本的な解説は省略します。
システムの構成について
今回は、以下のような要件があることを前提としています。
- ただS3に転送するだけではなく、ログビューアーとしてAthenaを利用する
- CloudWatch Logsからエクスポートされたログはメタデータが含まれているが、メタデータを除外した状態でS3に保存したい
- エラーログを検出したらSlackに通知する
これらの要件を満たすため、Kinesis Data Firehose + Lambdaを使う方法を選択しました。
構成は以下の通りです。
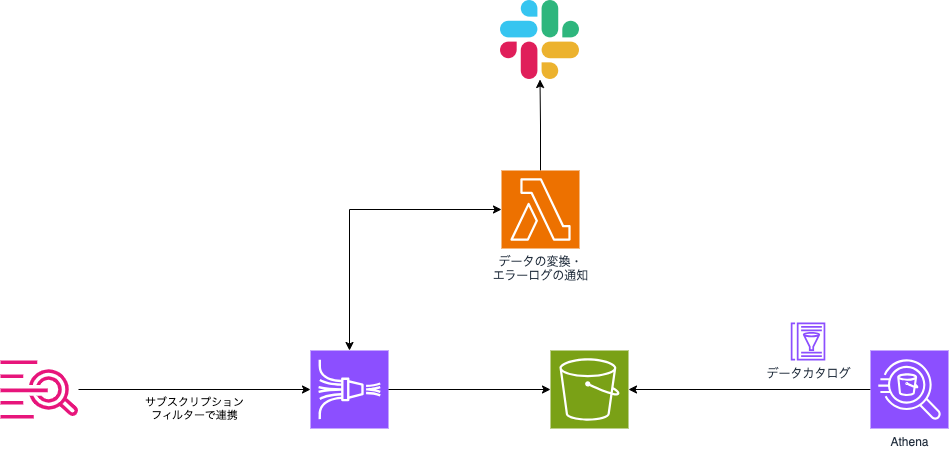
各サービスの役割
- CloudWatch Logs サブスクリプションフィルター: CloudWatch Logsに出力されたデータをフィルタリングしつつKinesis Data Firehoseへ連携します
- Kinesis Data Firehose: 定期的にCloudWatch Logsからログを受け取り、データ変換用のLambdaを呼び出しS3に転送します
- AWS Lambda: データの変換をします。また、エラーログを検出した場合適切なメンションをつけてSlackに通知します
- S3: ログを保存します
- AWS Glue データカタログ: AthenaからS3のデータを参照する際に必要なデータスキーマの定義です
- Amazon Athena: S3に保存されたログデータに対してSQLクエリを実行します
構築方法について
今回は以下の条件を前提として作成します。
- リソースの構築には主にterraformを用いること
- Lambdaは関数の作成はterraform、コードの反映は別の方法で行うこと
- Slackへの通知はWebhookを使うこと
- ログはJSON形式、かつデータカタログで定義されている通りのフォーマットで出力されていること
以下はterraformのコードの抜粋です。収集対象のロググループ名やSlackのWebhook URLはvariablesで指定する想定です。 (伏せ字の部分は事前にIAMロールとS3バケットを作って埋める必要があります)
terraform {
required_providers {
aws = {
version = "~> 5.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}
resource "aws_cloudwatch_log_subscription_filter" "this" {
name = "${trimprefix(replace(var.log_group_name, "/", "-"), "-")}-subscription-filter"
role_arn = "arn:aws:iam::xxxxxxxxxx:xxxxxxxx"
log_group_name = var.log_group_name
filter_pattern = ""
destination_arn = aws_kinesis_firehose_delivery_stream.extended_s3_stream.arn
distribution = "ByLogStream"
}
resource "aws_kinesis_firehose_delivery_stream" "extended_s3_stream" {
name = "${trimprefix(replace(var.log_group_name, "/", "-"), "-")}-stream"
destination = "extended_s3"
extended_s3_configuration {
role_arn = "arn:aws:iam::xxxxxxxxxx:xxxxxxxx"
bucket_arn = "arn:aws:s3:::xxxxxxxxxxxxxxxx"
prefix = "${trimprefix(var.log_group_name, "/")}/!{timestamp:yyyy/MM/dd}/"
error_output_prefix = "!{firehose:error-output-type}/${trimprefix(var.log_group_name, "/")}/!{timestamp:yyyy/MM/dd}/"
buffering_size = var.buffering_size_mb
buffering_interval = var.buffering_interval_seconds
compression_format = "GZIP"
cloudwatch_logging_options {
enabled = true
log_group_name = aws_cloudwatch_log_group.kinesisfirehose.id
log_stream_name = "DestinationDelivery"
}
processing_configuration {
enabled = true
processors {
type = "Lambda"
parameters {
parameter_name = "LambdaArn"
parameter_value = "${aws_lambda_function.this.arn}:$LATEST"
}
parameters {
parameter_name = "BufferSizeInMBs"
parameter_value = 1
}
parameters {
parameter_name = "BufferIntervalInSeconds"
parameter_value = 60
}
}
}
}
}
resource "aws_cloudwatch_log_stream" "this" {
name = aws_kinesis_firehose_delivery_stream.extended_s3_stream.extended_s3_configuration.0.cloudwatch_logging_options.0.log_stream_name
log_group_name = aws_cloudwatch_log_group.kinesisfirehose.id
}
resource "aws_glue_catalog_table" "glue_etl_log" {
database_name = "default"
name = "${trimprefix(replace(replace(var.log_group_name, "/", "_"), "-", "_"), "_")}_log"
description = "Glue ETLジョブのアプリケーションログ"
table_type = "EXTERNAL_TABLE"
parameters = {
EXTERNAL = "TRUE"
classification = "json"
"write.compression" = "GZIP"
}
storage_descriptor {
location = "s3://xxxxxxx${var.log_group_name}"
input_format = "org.apache.hadoop.mapred.TextInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
number_of_buckets = -1
compressed = true
ser_de_info {
serialization_library = "org.apache.hive.hcatalog.data.JsonSerDe"
parameters = {
"serialization.format" = 1
}
}
columns {
name = "timestamp"
type = "string"
comment = "タイムスタンプ(書式 2023-11-12T16:34:59+0000)"
}
columns {
name = "level"
type = "string"
comment = "ログレベル(INFO, WARN, ERROR, etc...)"
}
columns {
name = "message"
type = "string"
comment = "ログの本文"
}
columns {
name = "module"
type = "string"
comment = "ログの発生元モジュール(GlueのETLジョブの名称)"
}
columns {
name = "funcname"
type = "string"
comment = "関数名"
}
columns {
name = "lineno"
type = "int"
comment = "ログの発生元の行番号"
}
columns {
name = "traceback"
type = "array<string>"
comment = "トレースバック"
}
}
}
resource "aws_cloudwatch_log_group" "lambda" {
name = "/aws/lambda/${trimprefix(replace(var.log_group_name, "/", "-"), "-")}-parser"
retention_in_days = 7
}
resource "aws_cloudwatch_log_group" "kinesisfirehose" {
name = "/aws/kinesisfirehose/${trimprefix(replace(var.log_group_name, "/", "-"), "-")}-stream"
retention_in_days = 7
}
# Lambda関数の作成はterraformで行いソースコードの更新は別で行う
data "archive_file" "dummy" {
type = "zip"
output_path = "${path.module}/dummy.zip"
source {
content = "dummy"
filename = "dummy.zip"
}
}
resource "aws_lambda_function" "this" {
function_name = "${trimprefix(replace(var.log_group_name, "/", "-"), "-")}-parser"
handler = "lambda_function.lambda_handler"
role = "arn:aws:iam::xxxxxxxxxx:xxxxxxxx"
runtime = "python3.11"
filename = data.archive_file.dummy.output_path
memory_size = var.memory_size
timeout = var.timeout_seconds
environment {
variables = {
SLACK_WEBHOOK_URL = tostring(var.slack_webhook_url)
POST_SLACK_ENABLED = var.post_slack_enabled
}
}
depends_on = [
aws_cloudwatch_log_group.lambda,
]
}
variable "log_group_name" {
description = "ロググループ名"
type = string
}
variable "buffering_size_mb" {
description = "S3送信時のバッファリングサイズ設定(MB)"
type = number
default = 5
}
variable "buffering_interval_seconds" {
description = "S3送信時のバッファリング間隔設定(秒)"
type = number
default = 300
}
variable "post_slack_enabled" {
type = bool
description = "slackに通知するかどうか"
default = false
}
variable "slack_webhook_url" {
type = string
description = "slack webhook url"
}
variable "memory_size" {
description = "メモリサイズ(MB)"
type = number
default = 128
}
variable "timeout_seconds" {
description = "タイムアウト(秒)"
type = number
default = 20
}
次にデータの変換用のLambdaのコードです。runtimeはPython3.11を想定しています。
SlackのWebhookを使うのにrequestsを使っているため、デプロイする際には一緒にzipにしてデプロイする必要があることに注意してください。
処理の概要及び注意点としては以下の通りです。
- 転送されてきたデータはBase64 でエンコードされており、かつgzip 形式で圧縮されています
- 最終的にAthenaで参照させる想定であるため、規定のフォーマット以外のデータは送らないようにしておく必要があります。サブスクリプションフィルターのフィルターパターンを用いてフィルタリングするか、このLambdaでフィルタリングする必要があります
- 初期構築時に疎通確認用のメッセージがシステムから送られるため、この実装をするか転送されたデータを削除しないとAthenaでエラーになります
- 転送されてくるログのデータは1件のデータレコードに対してログデータが複数行になる場合があります。また、Athenaが読み取れるように改行区切りのJSON Lines形式で出力するようにします
import os
import base64
import json
import gzip
from io import BytesIO
import logging
import re
import requests
# ロギングの設定
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
output = []
for record in event['records']:
try:
# Kinesis Data Firehose のデータは base64 エンコードされています
payload = base64.b64decode(record['data'])
try:
with gzip.GzipFile(fileobj=BytesIO(payload)) as gzip_file:
decompressed_data = gzip_file.read()
except gzip.BadGzipFile:
logger.exception(f"Gzip 解凍エラー: recordId={record['recordId']}, payload={payload}")
# 解凍エラーは想定外であるため正常に処理できなかったこととする
output.append({
'recordId': record['recordId'],
'result': 'ProcessingFailed',
'data': record['data']
})
continue
try:
json_data = json.loads(decompressed_data)
except json.JSONDecodeError:
# 上述の疎通確認用のメッセージ等が流れてくるのを考慮して、パースエラーは転送対象から除外する
logger.exception(f"JSON 解析エラー: recordId={record['recordId']}, payload={payload}")
output.append({
'recordId': record['recordId'],
'result': 'Dropped',
'data': record['data']
})
continue
log_events = json_data.get('logEvents', [])
# 各 logEvent から "message" キーの値を抽出し、それをリストにまとめます
messages = []
for event in log_events:
message_json = event.get('message')
if message_json:
try:
message_data = json.loads(message_json)
if message_data.get('level') == 'ERROR':
post_slack(message_data)
# スペースを取り除いて文字列化しないとAthenaでエラーになる
compact_message = json.dumps(message_data, separators=(',', ':'))
messages.append(compact_message)
except json.JSONDecodeError:
logger.exception(f"'message' キーの JSON 解析エラー: recordId={record['recordId']}, message_json={message_json}")
output.append({
'recordId': record['recordId'],
'result': 'ProcessingFailed',
'data': record['data']
})
continue
json_lines = '\n'.join(messages) + '\n'
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(json_lines.encode('utf-8')).decode('utf-8')
}
output.append(output_record)
except Exception as e:
# 予期しない例外が発生した場合の処理
logger.exception(f"予期しないエラー: {str(e)}, recordId={record.get('recordId', '不明')}")
output.append({
'recordId': record.get('recordId', '不明'),
'result': 'ProcessingFailed',
'data': record['data']
})
return {'records': output}
def post_slack(log):
post_slack_enabled = os.environ['POST_SLACK_ENABLED']
slack_webhook_url = os.environ['SLACK_WEBHOOK_URL']
if "true" != post_slack_enabled.lower() or not slack_webhook_url:
logger.warn(f"Slack通知は無効化されています。log: {log}")
return
log_json = json.dumps(log)
# メンション作成
mentions = create_mention(log)
slack_message = {
'text': f"Error caused. {log_json} {mentions}"
}
# SlackのWebhook URLにPOSTリクエストを送信
response = requests.post(
slack_webhook_url, data=json.dumps(slack_message, indent = 2),
headers={'Content-Type': 'application/json'}
)
# レスポンスをチェック
if response.status_code != 200:
raise ValueError(f"Request to Slack returned an error {response.status_code}, the response is:\n{response.text}")
# slack設定読み込み
def read_slack_group():
with open('slack_group.json', 'r') as slack_group_file:
return json.load(slack_group_file)
# ログからメンション文字列作成
def create_mention(log):
slack_groups = read_slack_group()
mentions = ""
for slack_group in slack_groups.values():
if not slack_group['scripts']:
continue
# scripts名を|でつなげてパターン文字列にする
patterns = re.compile(r'|'.join(slack_group['scripts']))
# logのmoduleにscriptsが部分一致で該当するならメンションを付与する
if bool(patterns.search(log['module'])) and slack_group['mention']:
mentions += " <!subteam^{0}>".format(slack_group['mention'])
return mentions
また、Pythonと一緒に以下のようなJSONファイルを一緒にデプロイします。
{
"teamA": {
"scripts": [
"etl-jobA",
"etl-jobB"
],
"mention": "AAAAAAAA"
},
"teamB": {
"scripts": [
"etl-jobC"
],
"mention": "BBBBBBBB"
}
}
上記のJSONですが、以下のような構造になっています。
- チーム名
- スクリプト名
- SlackのメンションのID
ログの中にスクリプトの名称が含まれており、スクリプトの名称とマッチした場合そのチームに対してメンション付きでSlackにメッセージをポストする仕組みになっています。
これにより、新しくスクリプトを追加したチームはこのJSONを修正するだけでエラーログの監視ができるようになっています。
以下は実際にログをAthenaから参照した様子です。
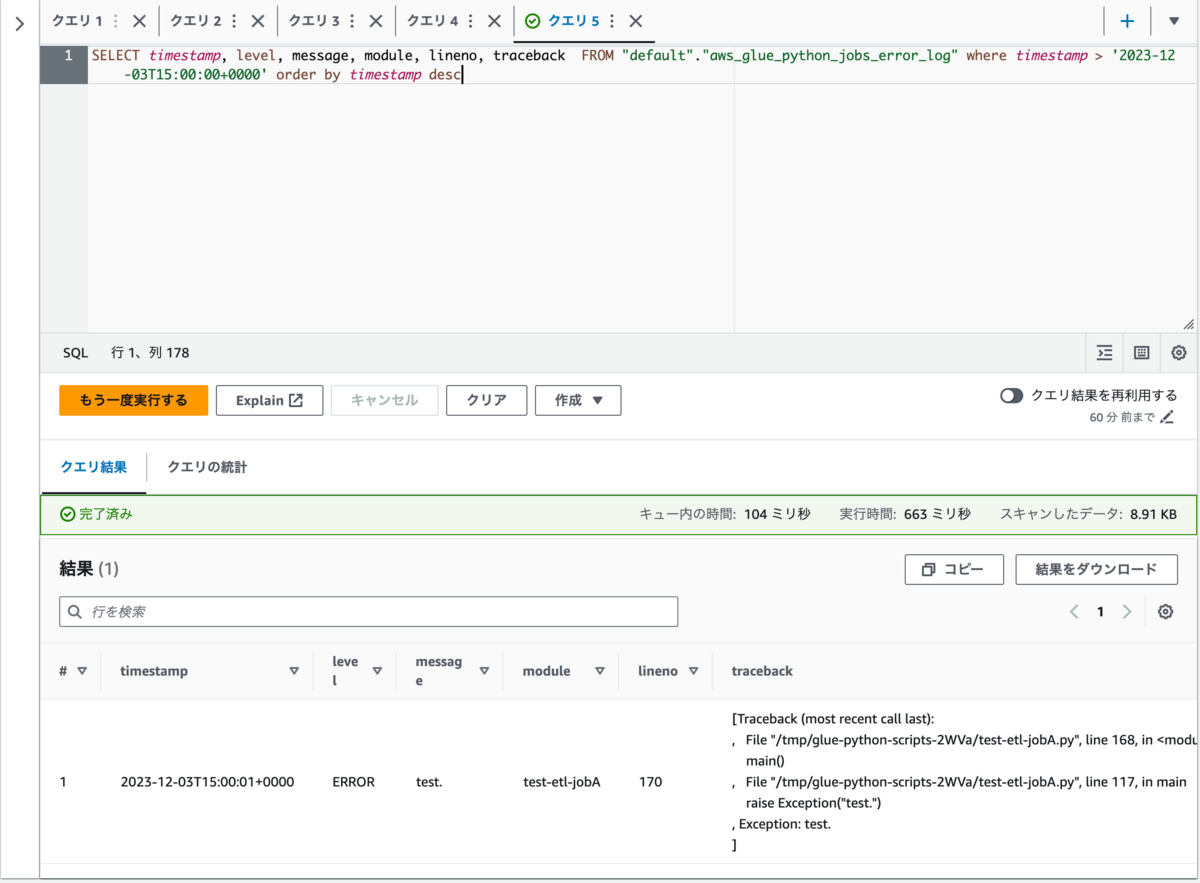
このように多くの方が慣れ親しんでいるであろうSQLクエリで結果を絞りつつログを参照することができます。
また、トレースバックのような改行が含まれているデータも改行されている状態で見ることができます。
ただし、ログの量が増えてくるとパフォーマンスが劣化したり、Athenaの料金は参照元のデータ容量に依存するため1クエリあたりの費用が高額になる可能性があります。
その場合はAWS Glue Data Catalogのパーティション・インデックスを検討する必要があります。
まとめ
CloudWatchにあるログをFirehoseを使ってS3に転送しつつ、エラーログのSlack通知を実装しました。
また、ログビューアーとしてAthenaを使うことにより、低コストでログの保存をしつつ慣れ親しんだSQLクエリでログの絞り込みを行うことができます。
今回のサンプルのように、terraformを利用しつつロググループ名をvariableを使って外部から注入するようにすれば、流用できるように構築することができます。
We are hiring!
みらい翻訳では、私たちと一緒にプロダクト開発を進めていただけるエンジニアを募集しています! ご興味のある方は、ぜひ下記リンクよりご応募・お問い合わせをお待ちしております。