
こんにちは。プラットフォーム開発部でリードエンジニアをしている chance です。
今回はEKSで実行しているDebeziumで、AuroraのFailOver時に自動復旧させる設定についてお話しします。また補足として、SpringBootなどのJavaアプリケーションでのFailOver対策についても触れています。
TL; DR
- Debezium の FailOver 対策としては、EKS の livenessProbe で tasks の state が FAILED になっていないかどうかを監視する。
- 通常の Java アプリケーションでは DNS キャッシュ TTL を調整の上、コネクションプールのテストクエリで read-only を見分ける。
はじめに
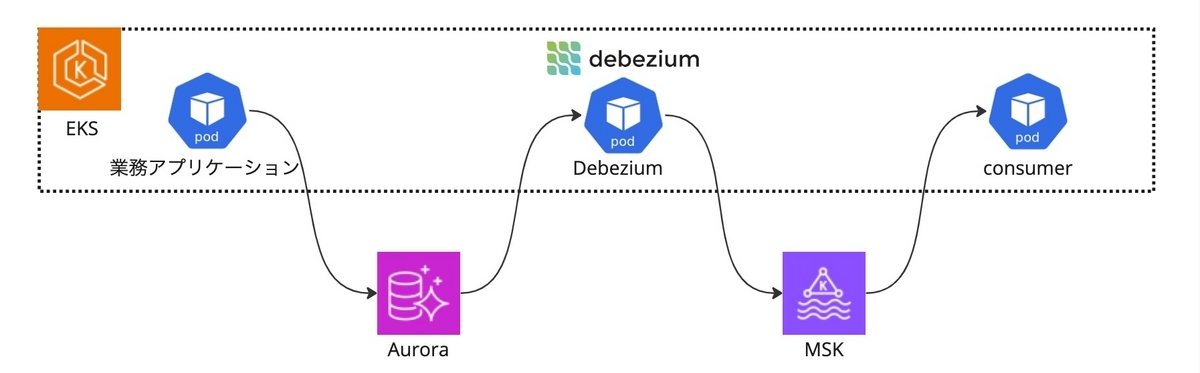
弊社ではイベント駆動のメッセージングのブローカーとして Kafka(AWS MSK) を利用しています。また、Kafkaへの書き込みとしては Outbox パターンを採用しており、Aurora からKafka への Producer として Debezium を利用しています。

Outbox パターンによってアプリケーションからの業務データとメッセージングのトランザクションの一貫性が保証されます。
この記事をお読みいただく方に Debezium 自体のご説明は不要かもしれませんので、サラッと書くと、Debezium は CDC(Change Data Capture) のための OSS です。具体的には、データベースのトランザクションログ(たとえば PostgreSQL の WAL ログ)を読んで更新差分を検知し、Kafka にメッセージを投げ込んでくれます。CDC 自体はデータベースのレプリケーションなどに用いられるものですが、Outbox パターンの実装方法としても最適です。
Debezium は常にデータベースに接続しており FailOver 発生時は自動で接続復旧を試みます。しかし、無事に接続が復旧できた後にエラーになることがあります。今回はこの対処についてお話ししていきます。
前提
AWS環境を利用しています。
Debezium は EKS 上の Pod で動かしており、データベースには Aurora PostgreSQL を利用しています。
以下のバージョンを利用しています。
- PostgreSQL 15
- Debezium 2.4.0
- (話に関係ないであろうもののバージョンは省略)
問題点
Aurora は FailOver 時にも素早く復旧してくれます。とはいえ、クライアントからすると一度接続が切れることには変わりありません。Debezium には接続が切れた際にリトライする機構が備わっており、再接続できた場合は処理を再開します。(v1.9あたりでリトライ周りの実装をいろいろと改善して頂いたみたいです。)
Release Notes for Debezium 1.9
しかし、ここで問題が発生しました。接続が復旧して Debezium が処理を再開する際、前回までの読み込み位置を確認して Replication Slot を更新しようとするのですが、これに失敗して処理を停止してしまいます。必ず発生するわけではなく、開発環境で試していると何回かに1回は発生しました。
エラーが発生する際のログの抜粋は以下です。
2024-01-26 07:12:59,697 ERROR WorkerSourceTask{id=<タスクID>} Task threw an uncaught and unrecoverable exception. Task is being killed and will not recover until manually restarted [org.apache.kafka.connect.runtime.WorkerTask]
org.apache.kafka.connect.errors.ConnectException: Unable to update filtered publication <パブリケーション名> for <スキーマ名>.<テーブル名>
at ...(省略)
Caused by: org.postgresql.util.PSQLException: ERROR: cannot execute ALTER PUBLICATION in a read-only transaction
at ...(省略)
2024-01-26 07:12:59,699 INFO || Stopping down connector [io.debezium.connector.common.BaseSourceTask]
PSQLException: ERROR: cannot execute ALTER PUBLICATION in a read-only transaction ということで、どうやら read-only なインスタンスに更新をかけようとしているようです。
さらに困ったことに、Debezium 自体(Javaプロセス)が停止してくれれば新しい Pod が立ち上がってくれるのでまだよいのですが、Java プロセスは生きたままなので CDC のみが停止した状態になってしまい、リカバリ作業が必要になってしまいます。
根本原因
Aurora は接続用のエンドポイントとしてライター用とリーダー用を用意してくれます。ライター用エンドポイントはライターのインスタンスに、リーダー用エンドポイントはリードレプリカのインスタンスに繋がります。
| endpoint | URLドメイン |
|---|---|
| writer | {クラスタ名}.cluster-xxxxx.{region}.rds.amazonaws.com |
| reader | {クラスタ名}.cluster-ro-xxxxx.{region}.rds.amazonaws.com |
当然、Aurora の挙動としては FailOver 後にエンドポイントの繋ぎ替えまでしてくれます。では、Debezium はなぜ FailOver 後にリーダーインスタンスに接続してしまうのでしょうか。
ひとつには、Java の DNS キャッシュの影響が考えられます。Aurora のエンドポイントのドメインの名前解決をすると最終的にはインスタンスの IP アドレスが返ります。このため、Java は実際にはインスタンスと TCP 接続を結んでいることになります。

Java は DNS の結果を(デフォルトでは)無制限にキャッシュするため、接続のたびに名前解決をすることなく FailOver 後も FailOver 前と同じインスタンスに繋ぎにいったと推測されます。

解決策1
Java の DNS キャッシュ対策として、TTL の値を設定して定期的に DNS 問い合わせをやり直すというプラクティスがあります。
// SpringBootアプリケーションで、プロパティで指定する場合 package xxx.yyy.zzz; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import java.security.Security; @SpringBootApplication public class DemoApplication { // JavaはDNSキャッシュをデフォルトで永続保持してしまいAuroraのfailoverなどに対応できないため、ttlを指定する。 static { Security.setProperty("networkaddress.cache.ttl", "10"); Security.setProperty("networkaddress.cache.negative.ttl", "10"); } public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } }
また、コネクションプールのテストクエリを工夫する方法も有効なようです。こちらのブログを参考にさせていただきました。
# HikariCPの場合 spring: datasource: hikari: # transaction_read_only=offなら成功、それ以外は失敗するクエリにしておく。1/0とするとSQL自体が成立しないのでrandom()を利用している。 connection-test-query: select case when current_setting('transaction_read_only') = 'off' then 1 else random()/0 end
Consumer や WebAPI は SpringBoot で開発していたため、これらの設定をすることで FailOver 後も接続を失うことなく動作しました。
しかし、今回の Debezium の場合、TTL のオプションを指定しても事象解決しませんでした。また、コネクションプールに関する設定項目は見当たリませんでした。
JDBC 接続の初期化時に実行するクエリの設定はあるのですが、ここに上記のテストクエリを設定しても接続をやり直してくれず、うまく復旧できませんでした。
さらにソースコードを追い始めたところで、こればかりにあまり時間は取っていられないと一旦手を止めました。
視点を変えて異常状態を検知してPodを再起動できないか?という検討に切り替えます。
解決策2
最初に思いついたのは、エラーログ監視をトリガーに再起動する方法です。エラー内容は判明しているのだからこれを監視しておいて Pod 再起動を呼び出せないかと考えました。しかし、ログフィルターから Pod の再起動コマンドを発行するまでにかなり遠回りすることになるので構築・保守の負担が増えることと、EKS 外部からの操作のための権限設定も必要になりそうなので、もう少しシンプルに解決したいところです。
ところで、Debezium は実体としては Kafka Connect の Connector として動いています。Connector にヘルスチェック機能はないのだろうか、ということで見てみると、
ありました。
GET /connectors/(string:name)/tasks/(int:taskid)/status
Connector と Task がそれぞれ state を持っているようです。

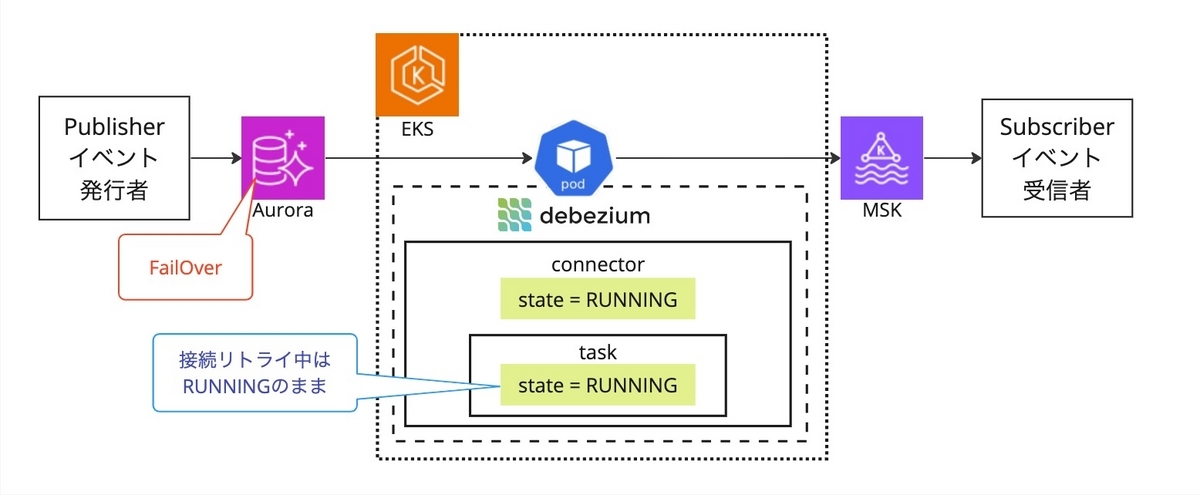
実際に FailOver をさせて状態遷移を見てみると、FailOver 直後に JDBC 接続を失い接続リトライ中は stateは RUNNING のままでした。
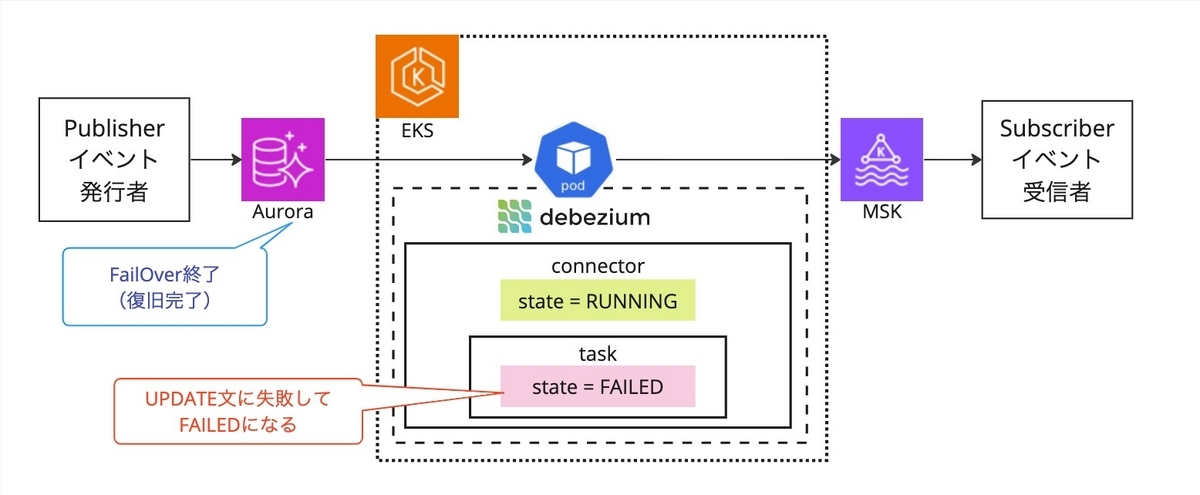
FailOver 完了後に例のごとくリードレプリカに更新にいって例外が起きたところで、stateは FAILED に陥りました。
これがトリガとして使えそうです。kubernetes には pod の状態を識別するための Probe という仕様があります。
| 種類 | 用途 |
|---|---|
| startupProbe | 起動したことを識別するための条件 |
| livenessProbe | 再起動が必要であるかを識別するための条件 |
| readinessProbe | (APIなどの場合に)serviceから接続できる状態かを識別するための条件 |
今回の事象に対処する前は、startup も liveness も 8083 ポートの / を実行させていました。とりあえず connector が API を受けられる状態であるかどうかだけを見ていたためです。(service 経由で呼び出されないため、readiness は設定しません。)
### 変更前 livenessProbe: httpGet: path: / port: 8083 scheme: HTTP timeoutSeconds: 2 successThreshold: 1 failureThreshold: 1 periodSeconds: 60
今回の調査で、FailOver 起因で Tasks の state が FAILED になることがわかったので、livenessProbe を以下のように変更します。Debeziumの 仕様上並列処理はしないので、タスクIDは 0 で決め打ちしています。
### 変更後 livenessProbe: exec: command: - "sh" - "-c" - "curl -s http://localhost:8083/connectors/<コネクタ名>/tasks/0/status | grep -v '\"state\":\"FAILED\"'" timeoutSeconds: 2 successThreshold: 1 failureThreshold: 1 periodSeconds: 60
これにより、state= FAILED を検知した瞬間に再起動がかかるようになりました!
まとめ
EKS で Debezium を利用している場合に、Aurora の FailOver 時に自動復旧する事例を紹介しました。ステータスの見分けかたについてはもう少し精査が必要かもしれませんが、稼働状況を監視しつつ対応していこうと考えています。
今回の件がどなたかのお役に立てれば幸いです。
最後に
みらい翻訳では、エンジニアを募集しています。
ご興味のある方は、ぜひ下記リンクよりご応募・お問い合わせをお待ちしております。