 この記事は、みらい翻訳のカレンダー | Advent Calendar 2022 - Qiita の13日目です。
この記事は、みらい翻訳のカレンダー | Advent Calendar 2022 - Qiita の13日目です。
こんにちは。プラットフォーム開発部でリードエンジニアをしているchanceです。
今回は コンテナ(AWS ECS on Fargate)上での Java(JVM) のメモリのお話をします。
概要
先日、商用環境の ECS で試運転させていた Java アプリのコンテナが度々再起動してしまう事象がありました。 幸い、まだリリース前だったためサービス影響はありませんでしたが、原因特定のためさっそく調査を開始しました。
コンテナの停止理由は OutOfMemory だったのですが、Java のログにはそのような出力はされていませんでした。Java ヒープの枯渇ではなく OS のメモリを使い切っていたようです。AWS のコンテナの場合、メモリを使い切るとコンテナが強制終了されるとのことでした。 (参考:Amazon ECS における OutOfMemory エラーのトラブルシューティング)
Java がメモリを使い切っていないのに、OS のメモリが枯渇するのはどういうことだろう、というところからこの件の原因調査・対策を通して JVM のメモリまわりを久しぶりに色々と調べ直しましたので、内容を整理してシェアしたいと思います。
背景
簡単に今回の背景や経緯などを先にお話しします。
環境構成
状況
商用環境にデプロイ後、数日程度稼働させると ECS タスクが停止してしまっていました。 コンテナ停止時の ECS のマネジメントコンソールから、メモリが足りないことが原因と判明しました。
状況の理由 OutOfMemoryError: Container killed due to memory usage 終了コード 137
とある日の 24 時間分のグラフです。上が OS から見たメモリ使用率、下が JVM のメモリ使用量になります。


OS のメモリ使用率は徐々に上昇していて、99%に到達してから数時間後に解放(コンテナが停止)され、再起動されている様子が見られます。 しかし、同時間帯の JVM のメモリ使用量では使い切ったようには見えません。(1024M あるはずのメモリに対して、Heap と NonHeap の合計で 700MB 程度を示しています。)
このコンテナでは Java しか動かしておらず、サイドカーコンテナもいないため、犯人は Java しか考えられません。 OS から見たらメモリを使い切っているのに、JVM から見たら使い切っていない、これはどういう状況でしょうか。
JVM のメモリ関連の調査のポイントなどと併せて説明していきます。
Javaパラメータ確認
まずは問題の切り分けを行うため、想定通りに設定値が反映されているかを確認します。
JVM の各種パラメータ出力設定
Java の起動オプションに以下を追加すると、起動時に各種パラメータがどのような値に設定されるのかをログ出力してくれます。
-XX:+PrintFlagsFinal
全パラメータが表示されるため一部抜粋しますが、例えば、以下のような出力が得られます。
[Global flags]
double InitialRAMPercentage = 75.000000 {product} {command line}
double MaxRAMPercentage = 75.000000 {product} {command line}
コンテナで稼働させていることでOSのメモリサイズが適切に読み込めていない可能性も考えましたが、Java10 以降では以下のパラメータが有効になっており、問題はなさそうです。
bool UseContainerSupport = true {product} {default}
ヒープサイズの指定は確かに意図通りに読まれているようでした。上記以外のメモリ関連のパラメータも確認できますが、想定外のところはありませんでした。
仮想メモリ
そもそも、ヒープサイズをinitial=maxで設定したのに、OSのメモリ使用率が起動直後に確保されないのはなぜでしょうか。
この説明のためにはまず、仮想メモリと物理メモリとプロセスの関係をおさらいします。
プロセスとしては、起動した段階でそのプロセスが使いうるメモリ領域を予約しようとします。特に書いたり消したりを繰り返したい場合は、連続したメモリ領域であった方が都合がよいためです。
プロセスのメモリ管理は OS (カーネル)を介して行われますが、プロセス起動時の確保は「予約」扱いであり、この時点では仮想メモリのアドレスのみが割り当てられます(物理メモリはまだ割り当てられません)。物理メモリが確保されるのは、プロセスが実際にメモリに書き込みを行うタイミングになります。
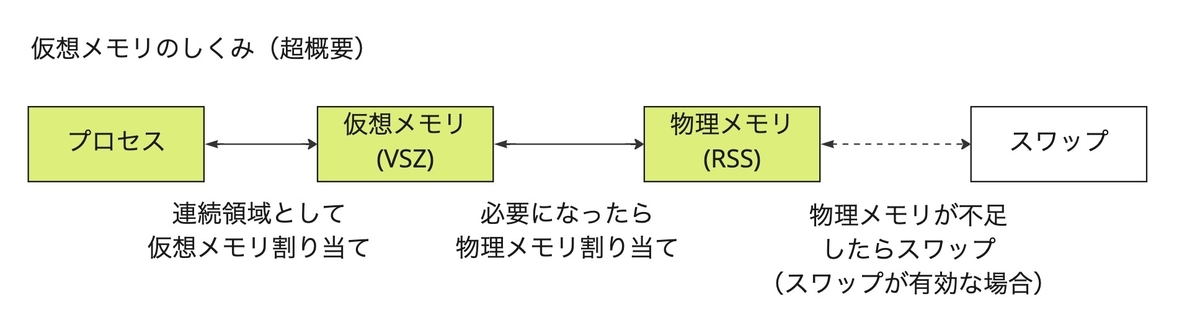
話を今回の件に置き換えると、ヒープ領域を 75%で指定した場合、起動時点で仮想メモリは 75%分押さえられますが、物理メモリの使用率として現れるのは Java プロセスが実際にメモリに書き込みを行ったタイミングとなります。
OS のメモリ使用率が上昇傾向を見せる理由は分かりました。では、JVM のメモリ使用量と計算が合わないのはなぜでしょうか。
JMX メトリクス
すでに先述のグラフでも出していますが、JVM の状態をモニタリングするために JMX メトリクスを取得できるようにしていました。 これを用いて、Java が "used" だと言っているメモリ領域の内訳を確認していきます。
JMX メトリクス出力設定
取得方法はいくつかあります。
SpringBoot の場合、Actuator を利用すると他の運用系の機能も使えて便利です。
Spring Boot 本番対応機能 - リファレンスドキュメント
今回のアプリは SpringBoot ではなかったため、Prometheus の JMX Exporter を利用しました。
詳細な導入手順はドキュメントをご参照ください。簡単にご紹介すると、ライブラリのパスとポート、設定ファイルを java 起動時のデバッガオプションで指定してあげるだけで JMX API が立ち上がります。
java -javaagent:./jmx_prometheus_javaagent-0.17.2.jar=8090:config.yaml -jar app.jar
上記で有効にした JMX API を、監視エージェントから定期的に実行することでメトリクスを取得していきます。今回は CloudWatch Agent を利用しました。
こちらも手順詳細は省略しますが、メモリ使用量調査の観点で一言だけ補足をすると、今回はサイドカーコンテナとしてではなく ECS の別サービスとして起動させました。このため、CloudWatch Agent が Java アプリとリソースを食い合うことはありません。
JMX メトリクスで見られるメモリの内訳
メモリ関連の JMX メトリクスでは、ヒープや非ヒープ領域の内訳を以下の区分けで見ることができます。
- ヒープ領域
- Eden : オブジェクト生成時に格納される領域。
- Survivor : Old に入れるかどうかの選別中に格納される領域。
- Old : Eden/Survivor で解放されない場合に格納される領域。
- 非ヒープ領域
また、各メモリ領域毎に init/used/committed/max という値が確認できます。
- init : 最初に仮想メモリを予約する量。(設定値)
- used : 現在物理メモリを占有している量。(実測値)
- committed : 仮想メモリを割り当てられた量。(実測値)
- max : 仮想メモリを予約する際の上限とする量(設定値)
ここでのポイントは、 used は「プロセスが物理メモリを割り当てられた量」ではなく、「今まさに値を格納している量」という点です。Java は一度確保したメモリを GC によって解放しますが、OS から見た物理メモリアドレスを解放するわけではありません。このため、OS から見た物理メモリの使用量よりも JVM の used が少ないという状況が生まれます。
先述のグラフでメモリ使用率 99%に到達した時刻の JVM メモリ領域の内訳を、JMXメトリクスから出しました。
| 領域 | init | used | committed | max |
|---|---|---|---|---|
| Non Heap | 7,667,712 | 131,834,288 | 137,900,032 | 1,325,400,064 |
| Heap | 805,306,368 | 214,739,944 | 805,306,368 | 805,306,368 |
| --- | --- | --- | --- | --- |
| 合計 | 812,974,080 | 346,574,232 | 943,206,400 | 2,130,706,432 |
JMX メトリクスからの考察
ヒープ領域については、 committed はパラメータで指定通りの値を確保しているが、used は先述のグラフ程度しか使っていないということのようです。現状がそうというだけで、状況によっては used は committed まで使い尽くす可能性があります。
非ヒープ領域については、used と committed はほぼ一致します。max の値は多いのですが、基本的に実際に必要な分しか確保されません。(クラスデータなどは動的な書き込みや削除が不要なため、メモリのアドレスも連続で確保する必要性が薄い。)
上記の表からして、ヒープの used が少ないうちは良くても、非ヒープ領域(Metaspaceなど)が140MB程度必要となると、明らかにヒープを大きく取りすぎであろうことは明白です。この時点で、今回の事象に関して取りうる対策は「ヒープサイズを小さく設定すること」になります。
それにしても1024MBのOSメモリを100%使い切るにしては計算が合わないことが心残りです。JMX メトリクスでは観測できない何かがあるのでしょうか。というところで、調査を続行しました。
GC ログ
GC ログから何かヒントが得られないかと思い、こちらも調査しました。
GC ログは先述の JMX メトリクスと違い、Garbage Collection というイベント発生の度にログ出力されます。たかだか数秒おきの定点観測であるメトリクス取得では概況までしか掴めませんが、GC ログからは GC の発生直後に各領域がいくらになったのか、GC が何回発生しているのか、などを正確に把握することができます。
GC のアルゴリズムについての解説は他の多くの優れた記事にお任せしますが、簡潔にまとめると以下の 4 種類になります。
| 種別 | GC スレッドの動作 |
|---|---|
| Serial | GC 実行時はアプリスレッドを停止する。シングルスレッドで GC を行う。 |
| Parallel | GC 実行時はアプリスレッドが停止する。マルチスレッドで GC を行う。 |
| CMS | young GC はアプリスレッドを停止し、old GC はアプリと並列実行する。 |
| G1 | ヒープ領域を小さいリージョンに分割し、リージョンごとに CMS を行う。 |
Java 9 以降では G1GC がデフォルトとなっていますが、正確には実行環境のスペックなどから自動判定(エルゴノミクス)されるようです。
例えば CPU=256,Memory=1024 の Fargate で GC アルゴリズムを明示的に指定しない場合は Serial GC が選択されました。
今回は -XX:+UseG1GC オプションを指定して明示的に G1GC を採用していました。
GC ログ出力設定
Java 8 の頃は GC ログ出力のオプションが統一されていなかったようですが、現在は統一した仕様が定義されています。
出力内容や出力先の設定は上記リンクをご参考にしてください。ひとまず標準出力に出すには、以下の起動オプションを付与します。
-Xlog:gc*
出力例はこのようになります。
[69036.921s][info][gc,phases ] GC(353) Pre Evacuate Collection Set: 0.1ms [69036.921s][info][gc,phases ] GC(353) Evacuate Collection Set: 33.2ms [69036.921s][info][gc,phases ] GC(353) Post Evacuate Collection Set: 0.4ms [69036.921s][info][gc,phases ] GC(353) Other: 0.3ms [69036.921s][info][gc,heap ] GC(353) Eden regions: 33->0(34) [69036.921s][info][gc,heap ] GC(353) Survivor regions: 5->4(5) [69036.921s][info][gc,heap ] GC(353) Old regions: 230->234 [69036.921s][info][gc,heap ] GC(353) Humongous regions: 12->12 [69036.921s][info][gc,metaspace ] GC(353) Metaspace: 74827K->74827K(1118208K) [69036.921s][info][gc ] GC(353) Pause Young (Prepare Mixed) (G1 Evacuation Pause) 277M->248M(768M) 34.201ms [69036.921s][info][gc,cpu ] GC(353) User=0.01s Sys=0.00s Real=0.03s
コンテナで動かすアプリケーションではログは標準出力にまとめることがプラクティスになっていますが、GC ログは上記のように 1 度で複数行のログが出力されるため、他のログの可視性を落とす可能性があります。ログを適切にルーティングする仕組みも併せて考慮したいところです。
GC ログからの考察
今回に関しては、GC ログからは原因究明には至りませんでした。ただし、以下のことがわかりました。
- GC によってメモリ領域は適切に解放されており、メモリリークしている様子はない(used のグラフは正しい)
- Old のリージョンを拡張するタイミングで OS のメモリも大きく上がる(リージョンは G1GC 特有の概念)
2点目の事実から、used の値が少ないままでもリージョン数は増やされることがあり、確保したリージョン数が物理メモリの使用率に反映されることが確認できました。JVMが実質使っているメモリは少ないままなのにOSのメモリ使用率が増えていく原因はここにあったようです。
しかし、これはあくまで予約確保されたヒープサイズ内でのメモリ使用量の話です。OSのメモリ使用率とJVMのメモリ使用量が合わない原因がまだ特定できていないため、次の調査に入りました。
NMT(Native Memory Tracking)
ネイティブ・メモリー・トラッキング(NMT)は、Java HotSpot VMの内部メモリー使用状況を追跡するJava HotSpot VM機能です。
(公式ドキュメントより抜粋)
NMTを利用することで、ヒープ以外の領域を含めて詳細にメモリ使用量をトラッキングできるようになります。
しかし、これを有効化すると 5∼10% のオーバーヘッドがあると公式でも案内があるため、調査・検証時のみ利用するのがよさそうです。
出力手順と出力例
デフォルトでは無効なため、以下の Java 起動オプションを追加することで有効化できます。
-XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary
実行中にトラッキング情報を見る場合は、jcmd も必要です。(つまり、実行環境(JRE)だけでなく開発ツール(JDK)が必要。)
実行中でなく停止直前の出力のみでよければ、jcmd がなくても以下のオプションを追加することでログ出力が可能です。
-XX:+PrintNMTStatistics
出力例は以下の通りです。こちらに関しては本番環境に仕込むのは憚られたため、開発環境での出力となります。(デプロイしたアプリは同じものです。)そのため、先述のグラフとの数値上の関係性はありません。
Total: reserved=2314892257, committed=987055073
- Java Heap (reserved=805306368, committed=805306368)
(mmap: reserved=805306368, committed=805306368)
- Class (reserved=1119270276, committed=51295620)
(classes #11039)
( instance classes #10539, array classes #500)
(malloc=1488260 #22781)
(mmap: reserved=1117782016, committed=49807360)
( Metadata: )
( reserved=44040192, committed=43253760)
( used=42123120)
( free=1130640)
( waste=0 =0.00%)
( Class space:)
( reserved=1073741824, committed=6553600)
( used=5986728)
( free=566872)
( waste=0 =0.00%)
- Thread (reserved=23220688, committed=1331664)
(thread #22)
(stack: reserved=23117824, committed=1228800)
(malloc=78432 #134)
(arena=24432 #42)
- Code (reserved=254681352, committed=16707848)
(malloc=1048840 #5140)
(mmap: reserved=253632512, committed=15659008)
- GC (reserved=75038479, committed=75038479)
(malloc=11493135 #10070)
(mmap: reserved=63545344, committed=63545344)
- Compiler (reserved=1742642, committed=1742642)
(malloc=30706 #382)
(arena=1711936 #10)
- Internal (reserved=810841, committed=810841)
(malloc=778073 #1784)
(mmap: reserved=32768, committed=32768)
- Other (reserved=144, committed=144)
(malloc=144 #9)
- Symbol (reserved=12930864, committed=12930864)
(malloc=11809480 #135759)
(arena=1121384 #1)
- Native Memory Tracking (reserved=2895960, committed=2895960)
(malloc=8472 #105)
(tracking overhead=2887488)
- Shared class space (reserved=17444864, committed=17444864)
(mmap: reserved=17444864, committed=17444864)
- Arena Chunk (reserved=1224136, committed=1224136)
(malloc=1224136)
- Tracing (reserved=97, committed=97)
(malloc=97 #5)
- Logging (reserved=4816, committed=4816)
(malloc=4816 #192)
- Arguments (reserved=23650, committed=23650)
(malloc=23650 #516)
- Module (reserved=149552, committed=149552)
(malloc=149552 #2240)
- Synchronizer (reserved=139336, committed=139336)
(malloc=139336 #1146)
- Safepoint (reserved=8192, committed=8192)
(mmap: reserved=8192, committed=8192)
表にしてみます。
| reserved | committed | |
|---|---|---|
| Java Heap | 805,306,368 | 805,306,368 |
| Class | 1,119,270,276 | 51,295,620 |
| Thread | 23,220,688 | 1,331,664 |
| Code | 254,681,352 | 16,707,848 |
| GC | 75,038,479 | 75,038,479 |
| Compiler | 1,742,642 | 1,742,642 |
| Internal | 810,841 | 810,841 |
| Other | 144 | 144 |
| Symbol | 12,930,864 | 12,930,864 |
| Native Memory Tracking | 2,895,960 | 2,895,960 |
| Shared class space | 17,444,864 | 17,444,864 |
| Arena Chunk | 1,224,136 | 1,224,136 |
| Tracing | 97 | 97 |
| Logging | 4,816 | 4,816 |
| Arguments | 23,650 | 23,650 |
| Module | 149,552 | 149,552 |
| Synchronizer | 139,336 | 139,336 |
| Safepoint | 8,192 | 8,192 |
| ---------------------- | ------------ | ---------- |
| Total | 2,314,892,257 | 987,055,073 |
JMX メトリクスで取れているものもいくつかありますが、
- Java Heap : いわゆるヒープ領域(Eden + Survivor + Old)
- Class : Metaspace + Compressed Class Space
- Code : Code Heap
上記以外はここで初めて詳細が取れた値ということになります。
各領域の説明は公式ドキュメントにもありますがあまり詳しい説明ではないので、状況に応じて個別に調べる必要があるでしょう。
NMT からの考察
NMT を取得することで、他の手法で観測できない非ヒープ領域のメモリ使用量を確認することができました。
上記の出力結果は本番環境でメモリ枯渇した時のものではないとしても、JVMが何にメモリを使っているかがわかるようになっただけで十分です。
Thread や GC など、JMX や GC ログでは観測できない非ヒープ領域で 100MB 以上のメモリを使用していることがわかります。メモリが数 GB あるような OS 環境では誤差の範囲ですが、OS として 1024MB しかない環境での 100MB は 10%に相当するため、無視できない大きさとなります。
このことから、非ヒープ領域として200〜300MBを確保した状態で、ヒープ領域75%(≒800MB)を徐々に使おうとすると、1000〜1100MBに向けてメモリを使用していく状態となり、1024MBのメモリが枯渇することは時間の問題であったことがはっきりしました。
まとめ
今回の一件、表面上の問題点は「ヒープサイズを大きく取り過ぎたこと」になり、対策は「ヒープサイズを下げること」になります。(もちろん、それでヒープが十分であることが前提。)
しかし、そこから一段掘り下げて調査することにより、以下の知見を得ることができました。
また、調査のためのオプションなどは今後も活用できるため、メモリチューニングや問題点の早期発見に活かしたいと思います。
知見1. JMXメトリクスで監視できない非ヒープ領域の存在
メトリクスで監視できない非ヒープ領域のメモリ使用量も意識し、少なくとも以下には特に注意する必要があります。
- Thread : 1 スレッドにつき 1024KB が確保される。例えば Web コンテナで Tomcat が 200 スレッド使うような場合は要注意。
- GC : GC アルゴリズムによる。実測値で、SerialGC なら 3MB 程度だが、G1GC だと 75MB 程度。
知見2. G1GC におけるメモリの used の見方
G1GC はリージョン毎に old が解放されるため、used のグラフだけでは物理メモリの利用状況が視えません。
- Serial や Parallel の場合、Old を使い切って FullGC という仕組み故に
usedの挙動がわかりやすいが、CMS GC によって Old を使い切ることが減り、G1GC でリージョンが分割されることでさらに効率的になっている。(いいことである。) usedが増えなくてもリージョンは増やされることがある、という挙動を知っておく。- 状況が追いにくいだけで、今回の教訓から余裕を持ったヒープ設定にしておけばいいだけの話。
- とはいえ G1GC は CPU やメモリの使用量も増えるため、少ないヒープサイズでも G1GC を使うべきかどうかは一考の余地あり。
知見3. コンテナにおけるヒープサイジングの勘所
OS のメモリサイズに制限のあるコンテナ環境において、些細な非ヒープ領域の増減にも気を配る必要があります。
- メモリが数 GB あればヒープ 75%でも余裕かもしれないが、1024MB メモリでヒープ 75%は完全な悪手。
- 説明は省略したが、今回のアプリは常時起動でスケーリング不要なため、Fargate でなく EC2 という選択肢も取れた。コストとスペックのバランスや運用特性を鑑みた選定をしていきたい。
最後に
みらい翻訳では、エンジニアを募集しています。
ご興味のある方は、ぜひ下記リンクよりご応募・お問い合わせをお待ちしております。