
こんにちは。プラットフォーム開発部 EMのchikaです。
今回は、負荷試験(性能試験)の基本について改めて調べる機会があったので、それをもとに書きます。
きっかけは前々から読もうと思っていた Amazon Web Services負荷試験入門 を入手したので、本書の内容を参考に社内の勉強会で話すという目的でまとめたことです。(以降、特に明記せず「書籍」と記載しているところはこの書籍を指します)

- はじめに
- 負荷試験とは?呼称と定義について
- なぜ負荷試験を行うのか?
- 試験の実施にあたり決めるべきこと
- 目標値の決め方
- 負荷試験のアンチパターン、注意点
- さいごに
- 参考にしたもの
- We are hiring!
はじめに
今回は、負荷試験のことを知らない方や、直接実施したことがないことから曖昧な理解しかしていないといった方のために、負荷試験の定義や基本など、どちらかというと試験実施前にやることを改めて知ってもらう事が目的です。
「負荷試験ってどんなことをやるんだっけ?」「ツール使ってサクッとできるんじゃないの?」と思っている方には多少なりとも参考になればと思います。
説明すること
説明しないこと
- 負荷試験のツールの使い方や設定など
- 具体的なツール紹介や実行サンプルはありません
- 何もやってみてないので、実践的な内容を求めている方にはごめんなさい
負荷試験とは?呼称と定義について
負荷試験は、他にも負荷テスト、性能試験など、なぜか呼び方にばらつきがあるような気がしますが、これらは同じ意味なのでしょうか?正しくはどう呼べば良いのでしょうか。
ISTQBによると用語の定義としては以下のように整理されています。
- 性能試験(performance testing)
- 負荷試験(load testing)
- 予想される負荷をかけたときにシステムがどのような挙動をするか、要件を満たす性能が出るのか、どのくらいの負荷まで設計どおりに正しく動作するのかを検証する試験
- 性能試験の中の1つ
- 予想を超える負荷をかけて反応や不具合の有無を確認するテストはストレステスト(stress testing)と呼ぶ
ただ、負荷試験と言いつつ実際は負荷をかけないで行う試験や、ストレステストに相当する試験も含むなど、性能試験と同じようなスコープで負荷試験を説明しているところがかなりあるように思います。
書籍でも同様の印象ですが、ややこしいので今回は書籍にならって負荷試験という表現で記述することにします。
(補足)性能テストの分類
ISTQBの定義を取り上げましたが、ISTQBのシラバスをもとにJSTQBの翻訳チームの方が描かれた以下の図で覚えておくと理解しやすいです。
ただ、若干細かい分類だなぁという印象で、業界内の各現場ではあまりこのような統一見解がなされている気はしませんので、各現場で会話する際には注意した方が良さそうです。
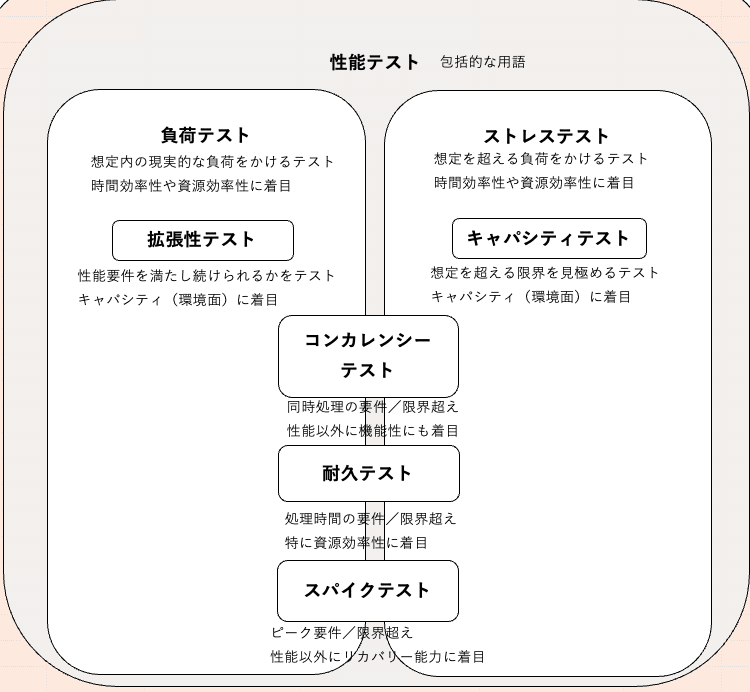
(出典:「性能テストに分類されるテストタイプの関係」JSTQB性能テストシラバスの補足(性能テストのテストタイプ)より)
(ローカルネタ)長安ってなに?
みらい翻訳の現場では「長安」と呼ばれているテストがあります。何のことだかわかりますか?
これは一般的には耐久テスト(endurance test)、ロングランテストと呼ばれるもので、「長期安定試験」もしくは「長期安定性試験」の略と思われます。ネットで調べてみると、略さない呼び方であればチラホラと見かけることができます。*1
私は長安という言葉はそれまでの職場では使った事がなかったので初めて聞いたときのインパクトはなかなかのもので、しばらくこっちのイメージが頭から離れませんでした。

他に「長安」という呼び方をしている現場の方がいらっしゃったらぜひ教えて下さい。
ちなみにこのテストは、たとえば2,3日間ずっと負荷をかけ続けることでだんだん遅くなったりしないか、想定外の不具合が起きたりしないか、というようなことを確認するテストです。原因のほとんどはメモリリークと言われています。
なぜ負荷試験を行うのか?
負荷試験は何のために行うのでしょうか?
先の負荷試験の定義にも書いた通り、予想される負荷がかかる状況下において、性能要件が満たされるであろうことを確認したいというのが一般的な目的です。
書籍では「クラウド時代の負荷試験の目的」として以下5つを挙げています。
- 各種ユースケースを想定し、それぞれにおけるシステムの応答性能を推測する
- ここで言うユースケースは、サービスイン後に負荷がかかりそうな状況
- 高負荷時におけるシステムの性能改善を行う
- 高負荷時においてのみ発生する異常を確認しながら改修を行う
- 目的の性能を提供するために必要なハードウェアを予め選定する
- 「ハードウェアの選定」はオンプレ的な表現だがクラウドでもスケーラブルな箇所ばかりではないのでスペック選定は大事
- スケール性の確認
- 実装されたアプリケーションが設計通りにスケールすること
- スケール特性の把握
- どこの部分を増強すれば性能が向上するか
1.で「推測する」と書いてあり、 「推測するな、計測せよ」 の格言*2をご存知の方にはダメな印象が浮かびますが、これは計測しないで推測するという意味ではなく、負荷試験で計測・分析ができても実際のユースケースにおける性能を「担保する」のは難しい( 担保できるのは「〜以上の性能は出ない」という上限の数字 でしかない)ということから著者が注意点の意味合いで言い換えた表現として用いています。
このあたり、著者の豊富な実体験を(痛い目を見たのだろうと)感じ取ることができます。
試験の実施にあたり決めるべきこと
負荷試験の目的(性能要件を満たすべきユースケース)
負荷試験を行う一般的な目的は先程挙げましたが、ここでは具体的にそのシステムで満たしたい性能要件や、性能を確認したいユースケース、考えられるリスクのことを指しています。
これが曖昧だと目標(ゴール)が定まらず、負荷試験を何のために実施するのか、どこまで実施してよいのかが分からなくなってしまいます。
なので、そのサービスにおいて性能要件に関わるユースケースを選定します。
例えば、
- キャンペーン告知やメディア掲載からの大量アクセスの流入
- 業務システムにおける業務開始時の大量ログイン
- バッチ起動時のWebとの同時利用
- 大量データ登録・更新処理によるDBコストやデータ整合性
- ○年後のデータ量を想定した画面の応答性能
などなど。
試験実施の前提条件
試験実施にあたっての前提条件で、例えば以下のようなことです。
- 試験対象とするシステムの範囲
- 外部システムやマネージドサービスを利用していることから試験の必要がない場合もあるため、品質保証しようとする範囲を明確にする
- データ量
- データ件数やサイズ
- サービスの利用者数、利用期間などから概算して出しておく
- 外部システムのレイテンシや利用上の制約
- 単位時間あたりの呼び出し回数の制限
- 最大同時接続数
- 負荷のかけ方
- どこのネットワークから負荷をかけるか
- 商用環境との環境差異
- 環境差異により何に影響してくると想定されるか
- 差異がない方がもちろん良い
負荷試験の実施環境
商用環境と試験環境の構成が大きく異なってしまうと、負荷試験は無意味になることがあります。感覚的には分かると思いますが、それはなぜでしょうか?
書籍では以下3点挙げられていました。
- 可用性やスケール性の確認
- ボトルネックの洗い出し
- 妥当な各種レポートの指標の計測
3.の計測した数値がそもそも信用できないというのもありますが、一番大きい問題は2.のボトルネックの洗い出し にあると思います。
構成している各サーバスペックやデータ量などが大きく異なると、リソースの使用状況が変わってくるため、負荷試験で確認したボトルネックに対してチューニングしても意味がない可能性が高く、また商用環境での運用時に発生しうる性能問題にもアプローチできません。 そのため実施環境は商用環境と同じ方が良いのですが、どうしても同じにできない場合もあります。
その場合、以下のような工夫を行います。
- 少なくとも構成としては商用環境と同じにして全体スペックを下げる
- ただし、スペックを下げた場合ネットワーク帯域も細くなることがあるので注意
- テスト対象とするシステム範囲を絞って、その範囲は商用環境と同じにする
- その範囲外を外部システムと見做してスタブサーバを構築する
- スタブからの応答時間はsleep処理を入れるなどして調整する
性能の目標値
クリアしたいユースケースや想定リスクに対して、どの指標が、どのような数値になったら負荷試験を終了できるのかというゴール設定です。
負荷試験の基本的な性能指標は、スループットとレイテンシ の2つを中心に、同時接続数ごとにそれぞれの目標値を設定するというのが一般的かと思いますが、ユースケースに合わせてリソースの使用量など他の指標とその目標値も検討します。
以下は設定する項目とその目標値の例です。
(掲載元:負荷テストの基本的な考え方と進め方(前編))
目標値の決め方
目標値はそれぞれの平均・最大の数値を決めてその間に収まるようにするというのが基本になります。
スループットの目標値
例えば、以下のような値から割り出して設定します。 最大を平均の2,3倍とざっくり出したりしてますが、80:20の法則で決めた方が実態に近づく場合もあると思います。
- 1日の利用者数(DAU)
- 正確な数が分からなくても、1,000人なのか1万人なのかというオーダーでOK
- MAUしか分からなくても30で割ればOK(2,3倍の安全率を掛ける)
- 1人あたりの1日の平均アクセス数
- サービス内容、ユーザーの行動パターンに依存する
- 例えば典型的なライトユーザのシナリオにおけるアクセス数の2,3倍(安全率)
- 1日の平均アクセス数に対する最大ピーク時の倍率
- 時間帯による変動があまりない標準的なサービスであれば概ね平均の2,3倍
上の数値を元にしたスループットの計算
DAU × 1人あたりの1日の平均アクセス数 = 1日の総アクセス数 ・・・A
A ÷ 86,400秒(1日) = 1日の平均rps ・・・B
B × 1日の平均アクセス数に対する最大ピーク時の倍率 = 最大rps
レイテンシの目標値
レイテンシの目標値が要件として決められている、というのは稀だと思っているので、決めるしかありません。 ユーザとして使ったときにそれなりに快適に使えると思う(これなら「速いね」と思える)時間の範囲を基準に、負荷が高いピーク時でもギリギリ許容できる(ユーザの不満につながらない)時間を最大とする、といった決め方で良いと思います。
一般的なWebサイトであれば、例えば画面の切り替わりは平均1〜2秒くらい、最大かかっても4秒以内には返ってきてほしい、など。
画面や機能によって許容範囲が変わると思うので、一律ではなくシナリオに沿って決める必要があります。
性能指標について補足
指標について補足しておきます。
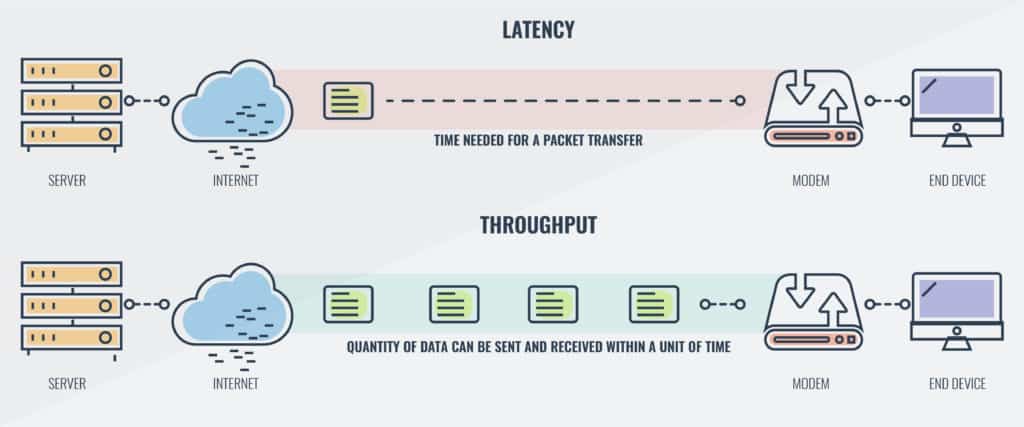 (レイテンシとスループット–違いを理解する より)
(レイテンシとスループット–違いを理解する より)
スループット
スループットは単位時間に処理を行う量のことで、Webシステムにおいては「1秒間に処理を行うHTTPリスクエスト数」= rps (Request Per Second)を指します。
レイテンシ
レイテンシは処理時間のことで、以下2種類。
一般的にはレイテンシと言ったら前者を指すことが多いですが、システム側で制御可能なのは後者のため、負荷試験では後者を扱うのが良いと思います。 (同一ネットワーク内など、ネットワーク遅延の影響を受けにくい条件下でなら前者で扱うことも可能だとは思います)
同時接続数
同時接続ってそういえばどういうこと?という疑問が一度は湧きます。
「せーの」で同時にアクセスすることを指してるのでしょうか?
これも一律の解はないですが、ログイン・ログアウトプロセスがあるアプリケーションであれば、ログイン〜ログアウトの間(いわゆるアクティブセッション中)のいずれかのプロセス中にあるユーザの数で決まります。 不特定多数にアクセスされるアプリケーションの場合は、1回のセッションあたりの平均滞在時間を単位時間としてその間のユーザ数・同一IP数で測るなどになります。
この同時接続の定義は、負荷をかけるツールの設定(スレッド数、Ramp-Up期間*3)にも影響します。
負荷試験のアンチパターン、注意点
書籍や元ネタ資料で、「やってはいけない」いわゆるアンチパターンについて、いくつか紹介されていますので、それらを参考に個人的に思っていることも加味して注意点を書き出してみます。
目的が曖昧
「念のためやっておきましょう」は思い当たる節のある方がたくさんいるのではないかと思いますが、これは試験結果から何も得られないので時間の無駄になります。
また、なんとなく実施してしまう場合は目標値も決まっていないでしょうから前回の結果と比較するくらいしかできません。
どのくらいの負荷に対してどのくらいの性能が出れば完了なのかのゴールが曖昧になってしまうので、目標値も数値として落とし込んでおく必要があります。
クライアントPCから負荷をかけてしまう
実際のユーザ環境からアクセスしないと、と思ってしまうかもしれませんが、手元のクライアントPCから負荷を掛けるのはネットワーク的に遠すぎてネットワーク回線の影響(帯域、レイテンシ)の方が大きくなってしまう可能性が大きいため、十分な負荷がかけられません。 エンドポイントとなるサーバと同一ネットワーク、または近いネットワークから負荷を掛ける必要があります。
また、1台のクライアントから負荷を掛ける場合、PCの方が先にボトルネックになってしまう可能性可能性が高いので、複数に分散するなど工夫が必要です。
いきなりシステム全体に対して試験実施してしまう
いきなりシステム全体に対して負荷試験を実施して目標値に到達できなかった場合、どこに原因があるのか切り分けが難しくなります。
切り分けして原因を潰していける範囲にしぼり、段階を踏んで何回か試験をするのが重要だと著者は述べています。
書籍では、以下のステップで試験を進める紹介をしていました。 さすがにここまでの粒度で繰り返すのはかなりの工数がかかりますが...
- 負荷試験ツールの試験
- フレームワークの最速値計測
- 参照系ページやAPI単体の試験
- 更新系ページやAPI単体の試験
- 外部サービス連携の試験
- シナリオ試験
- スケールアウト試験
- スケールアップ試験
- 限界性能試験
ボトルネックが特定できていない
試験を実施してもボトルネックが特定できないと、どこを改善すれば目標値に到達できるかが分かりません。ボトルネックにアプローチしない限り、スループットは上がりません。
また目標値に到達している場合でも、ボトルネックがわからないと増強する箇所が分かりませんし、次のボトルネックがどこになるかが分からないので、限界性能試験はその見極めに有効です。
スケール構成に対してのみ試験すればおk?
スケールアウトして性能担保できればよしよし、かもしれませんが、インスタンス単体で出る性能は大丈夫なのでしょうか?
実は1台あたりのrpsがとても少なく、本当は小さいインスタンス数台で捌ける程度の負荷を大きい(高価な)インスタンスを何台も横に並べてようやく捌いている、というのはお財布に優しくありません。
マネージドサービスに対する負荷試験?
ELBやCloudFrontなど、もともと自動でスケールするサービスに対して負荷試験をするのはお金の無駄です。 構成上設置するのは仕方ないですが、負荷をかけたい対象からは外して考えましょう。
サービスイン直前で実施する?
サービスイン直前で負荷試験を実施して目標値に到達できなかった場合、ちょちょっとスペックを上げれば大丈夫...ということはないので、間に合わない可能性が高くなってしまいます。
負荷試験のシナリオが流せるところまで開発が進んだら、なるべく早いタイミングで環境を作って実施した方が手戻りが小さくなります。
(とは言うものの、そんなに早いタイミングでは開発的にもインフラ構成的にも実施できる状態にするのは難しい、という現実はあります)
負荷試験は毎回必要?
ここまでは新規サービスの開発時の負荷試験の位置付けで捉えられたかもしれませんが、運用開始後、リリースの際にはかならず負荷試験は必要でしょうか?
既存システムの小さな改修などで、ボトルネックに影響がないと判断できる場合は負荷試験は必要ありません。
アプリケーションがやインフラ構成が大きく変わり、ボトルネックに影響がある or ボトルネックが移動する可能性がある場合は、負荷試験を実施した方が良いと思います。
ただ、経験的にはこれも実施するかどうかの基準を設けるのが難しく、個別判断になりがちです。そうすると、毎回実施判断するのが面倒になる上、リリース直前になって実施することになった場合はリードタイムに大きく影響します。また、小さいリリースだからとずっと実施しない判断が続いた場合、前に実施してから数年間実施されないということもあります。
なので、理想的には開発やリリースに伴って実施するのとは別に、負荷試験を行う環境を決めてリリースとは関係なく定期的に自動実行できる仕組みを設けておくことを合わせて検討したいところです。
これにより、リリース時に毎回判断したり、リリース直前の作業増加に悩まされることがなくなり、問題の早期発見にもつながります。これは例えば静的解析ツール(SAST)や動的解析ツール(DAST)を使ってセキュリティのシフトレフトを図ることと同じような考えです。
ただしその場合、ここまでで説明したような手厚い負荷試験を実施するわけではないので、確認できる観点は自動で冪等にできるものに絞る必要があるということと、そのような環境を用意し試験を継続的に実施するコストが許容できることが条件となります。
さいごに
ISUCONが業界で有名になったことにより、負荷試験を経験するのもそれなりに一般的になったかなぁとは思いますが、それでも現場で負荷試験を経験する人はあまり多くないのではと思い、基礎的な内容、特に実施前に知っておくべきことを中心にまとめてみました。
参考にした書籍は発売されて既に6年が経とうとしているので、紙面で紹介されている構成図のAWSアイコンをはじめ、まだコンテナ利用やマイクロサービスが一般的になっておらずEC2中心であるなど、一昔前のインフラ構成を前提にしていることなどは感じますが、基本的な考え方や目標値など基礎知識を学ぶ上では大変参考になる良書でした。相当遅れてではありますが、読めてよかったです。
ここまで長々とお読みになった方にとっても、何か1つでも参考になれば幸いです。
最後までお読みいただきありがとうございました。
参考にしたもの
- Amazon Web Services負荷試験入門 ――クラウドの性能の引き出し方がわかる
- Webアプリケーション負荷試験実践入門
- 書籍のもとになった資料
- ISTQBテスト技術者資格制度
Foundation Level Specialist シラバス 性能テスト担当者 日本語版 Version 2018.J01
- テストと言えばISTQB(JSTQB)
- JSTQB性能テストシラバスの補足(性能テストのテストタイプ)
- 上記の性能テストシラバスの日本語翻訳版の翻訳チームの方が書いてくれた補足記事
- 負荷テストの基本的な考え方と進め方(前編)
- 負荷テストの基本的な考え方と進め方(後編)
- Qiitaで見つけたとても勉強になる記事。
- 負荷テストのすすめ方入門 アーカイブ - pTune.jp
- 負荷テストやJMeterの使い方などの情報を専門的に発信してくれているサイト
- 安定したゲームリリースのためのWell Architectedと負荷テスト
- レイテンシとスループット–違いを理解する
以下、買ったけどサラッとしか読んでないので改めて読みたい。
We are hiring!
みらい翻訳では、私たちと一緒にプロダクト開発を進めていただけるエンジニアを募集しています! ご興味のある方は、ぜひ下記リンクよりご応募・お問い合わせをお待ちしております。
*1:いずれもあまり一般的な呼称でないからか、ググってもあまりヒットしません。どちらかといえば後者が医薬品試験の用語として多く引っかかります
*2:元ネタはRob Pike氏の Notes on Programming in C における格言から。Wikipedia UNIX哲学 及び こちらの記事が参考になる
http://dsas.blog.klab.org/archives/2017-12/52285859.html
*3:同時接続対象とするスレッドが全て起動するまでにかかる時間。
参考: https://ptune.jp/tech/make-modifications-for-load-testing/