 こんにちは。プラットフォーム開発部 EMのchikaです。
こんにちは。プラットフォーム開発部 EMのchikaです。
今回は、誰もが避けたい話題、障害対応について書こうと思います。
はじめに
最近何度か障害対応を経験したのですが、ちょっと久しぶりだったこともあって、「どうすれば良いんだっけ...」とかなりバタついてしまいました。
今までも障害対応の経験はあるし、頭では十分にわかっているつもり(少なくとも平常時は)、でも訓練不足でいざというときに体が反応しないし、知っているはずのことが頭からすっかり飛んでいる、そんな感覚でした。
そこで、訓練にはならないかもしれないですが今までに体験したこと、バラバラな知恵を書き留めて知恵袋の1つでも作ってみて、筋の通ったものとして自分の中に少しでも定着させたいなと思い、まとめることにしました。
周りの同僚にも何か1つでも参考になれば尚良しです。
参考書籍
今回、そんな気持ちに応えてくれそうな書籍があったことを思い出して改めて読んでみることにしました。
今回はこの本から個人的に覚えておきたいことをピックアップして、自分の体験や意見も交えてまとめていきます。
※以降、断りなく「書籍」と書いた場合はこの書籍を指します。
この本は以下の紹介の講演もあるので、こちらを視聴してざっくり概要を把握してからでも良いかと思います。
障害対応はなぜ難しいのか
経験することでしか身につかない
一般的な教育方法として、反復訓練をすることで人は経験をし、経験を何度も重ねることで血肉にしていきます。
設計・実装といった普段の業務は能力に合わせて簡単なものからやってみるなどの経験を重ねやすく、反復練習も可能です。またドキュメントからも頻繁に記述・参照されるので、ノウハウが定着しやすく、伝えやすいものです。
しかし、障害対応は能力に合わせた難易度に調整することは不可能ですし、基本的に同じ障害は二度起きない(はず)なので同じケースでの反復練習は難しいことが多いです。
そして、経験した人とそうでない人では圧倒的な差が出ます。
その空気を肌で感じて戦った人は鮮明に記憶に残るので、適切に振り返ることで次に生かせる教訓が得られるなど確実に経験値が積み上がります。障害に対する温度感についても、障害対応を経験をした人は危機意識が高く、恒久対応の重要性もよく理解しています。
対して、見聞きしただけの立場では頭で分かっていても体が動かないので対応できません。
突然デビュー戦を迎える
なので計画的に障害対応の経験を積んでおきたいところですが、話はそう簡単ではありません。
障害はリーダーをはじめチームのエース級が動く最優先対応事項になるため、若手に「ちょうどよいからこの対応で経験を積んでみようか」と任せる事案にはなりません。
通常の体制である限りは、特に若手は指示を受けて動く担当者として経験するにとどまります。
ではいつ障害対応のリーダー経験するのかといえば、他にできる人がいない時 です。
(例:深夜・休日、夏休み、リーダークラスが辞めた直後 など)
障害対応はスカウトもなく急にデビューすることになります。
(おまけ)障害は空気を読んでくれない?
障害はいつもタイミングの悪い時にやってきます。以下は都市伝説(現場あるある)なので数字的な根拠は何もないですが、こういう経験を立て続けにすると印象に残ります。ベテランエンジニアの方であれば、こういったネタを1つや2つ持っているのではないでしょうか。
- 人が少ない時(メイン担当者がいない、リーダー・マネージャーがいないなど)
- 属人化してるシステムほど、担当者がいないときに荒ぶる(気がする)
- 休んだときに問題が起きることが2,3度あると「肝心なときにいない」と言われる
- (リモートワークにて)たまたま出社したとき
- 最近個人的にこれを感じます笑
- 休み前
- 目処が立たないと週末を潰すハメになる
- 暫定対応が終わっても安心して休めない、週明けの障害報告が憂鬱


すぐ筋肉が落ちる、感覚が鈍る
消防士さんは日夜現場に出動して実戦していますが、現場に行かなくても日々訓練に励んでいます。
障害対応には日頃からの訓練で身につけた瞬発力が必要になります。
べき論で言えば、以下のようなことは頭に叩き込まれていないといけないレベルですが、
- 障害なのかどうかの判断
- 誰に何をどの手段で連絡するべきなのか
- 記録・報告のために押さえなければならない情報は何か
障害対応の経験が少ない現場では、これらは決まっていないか、決まっていてもそれが書かれたドキュメントが使われないので存在を忘れてしまいます。
障害が起きないのは良いことですが、平和な日々に慣れてしまうと完全に筋力が落ちてしまい、急に訪れた緊急事態に対して反射的に対応することができず、「あれ?何からすれば良いんだっけ…?どうしよう…」と焦って怖くなってしまいます。
頻繁に障害が起きているのが健全とは思いませんが、1年に1回くらいは経験した方が精神的にも鍛えられるので、何らか訓練をする仕組みがあった方がよいと思います。
防災の日に合わせた避難訓練や、年1,2回の情報セキュリティ研修の内容がどのくらい身についているかを考えると、年1回というのは最低限だなと感じます。
余談ですが、うちにある避難グッズセットの詰まったリュック、1年ほど前に購入してから未開封です…
障害対応の体制づくりの鉄則
一人でやらない
障害対応は時間との戦いです。目の前の状況を見てどうにかしたい気持ちで「とりあえず」手を打ちたくなることもありますが、作業は急ぎつつも、ミスのないように慎重に行わなければなりません。
そんな慎重さが求められる調査・復旧作業だけで精一杯なのに、顧客・営業・経営陣などから「何が起きてる!?」「今どうなってる!?」「影響は?」と次々に問い合わせが入ったりして焦る気持ちに拍車を掛けてきます。
これらの問い合わせを交通整理しなければならない上、問い合わせベースでなくても状況報告はこまめにする必要があり、調査・復旧作業をしながら情報を整理して報告するのは無理です。
必ず誰か応援を呼んで、複数人(最低2人)で対応するようにしましょう。
インシデントコマンダーを決めて作業と窓口を切り離す
インシデントコマンダーとは、障害対応における現場リーダーであり、社内ステークホルダーとの窓口になる役割のことで、書籍に出てくる一番重要なキーワードです。
主な役割は以下の通りです。
- 作業担当者への実施指示(旗振り)
- 障害対応要因や関連チームの招集・組成・維持(体制構築)
- 顧客、関連チームとのコミュニケーション(窓口)
- 障害の発生と終息の宣言
- 情報の整理と更新(障害状況ボード)
- 外部向けのオフィシャルな障害報告書(レポーティング)
(「システム障害対応の教科書」3.1「システム障害対応の登場人物の概要と体制」より抜粋)
肝心なのは、実際に障害を解決する作業担当とは別の人が担当するということです。
窓口担当を分けることで関係各所からの連絡に追われて作業が遅延するリスクを避けられ、作業担当と別の人間が確認をすることで作業ミスや調査漏れ、思い込みなどを防止する効果もあります。
インシデントコマンダーになるのは誰?
インシデントコマンダーは対象サービス・システムに対する深い技術知識は必要ない、と言われており、それよりもマネジメントスキル、コミュニケーションスキル、迅速な意思決定が求められます。
とは言え、上の役割リストを眺めると正直ちょっと多くね?… 敷居高ぇ、、とビビる気持ちも分かります。
この役割は複数人で担うこともあるので、1人でやらなければいけないと思わず、障害の規模ややることの多さに応じて複数人で手分けすればよいかと思います。
旗振り役と窓口と記録役、これを2人くらいで分担すると負荷が少なくなると思います。
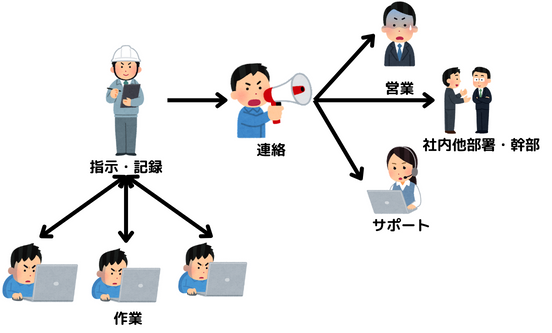
また、このインシデントコマンダーの役割は組織上の上長(マネージャー)が担うことになりがちですが、書籍では以下の理由から上長に固定しないことを勧めています。
- 上長が捕まらないことが多い
- 担当を固定化すると部下の成長が止まる
- 上長が必要な能力を備えているとは限らない (「システム障害対応の教科書」3.2.3「障害対応要員や関連チームの招集・組成・維持(体制構築)」より抜粋)
教育の観点からも、インシデントコマンダー=上長という固定観念は持たず、誰が担っても良いものだと認識した方がよいかと思います。
(補足)インシデントコマンダーとインシデントコマンドシステム(ICS)について
インシデントコマンダーについては、以下のサイトでも定義や心得などがすごく分かりやすく説明されています。
後者のPagerDutyの資料は「トレーニング資料」となっており具体的な現場のコミュニケーションにまで言及されていておすすめです。
特に目立つ赤色注釈で強調されている以下の一文はめちゃくちゃ刺さりました。
傍観者効果を引き起こすため、「誰かできますか」は言わないでください。タスクは誰かが拾うことを期待せず、常に特定の誰かに直接割り振ります。
またインシデントコマンダーの語源は、ICS(Incident Command System)から来ています。
ICSは、米国で開発された災害現場・事件現場などにおける標準化された管理システムのことで、災害・事件の種類を問わず、日常の事件・事故からテロ事件・ハリケーン災害などの危機管理まであらゆる緊急事態対応で使用されているフレームワークです。
(参考:インシデント・コマンド・システム - Wikipedia )
Googleのインシデント管理システムはこのICSに基づいているとのことです。
障害対応で覚えておきたいこと7つ
ここからは書籍の中から「これ大事!」と思ったポイントと、私自身がこれまでの経験で身にしみたことを合わせて、7つ取り上げます。
1. 初動は本当に重要
障害対応の開始プロセスは以下のような流れになります。
- イベントの発生(アラート発報、ユーザーからの申告)
- イベントを検知して事象を確認
- 一報(関係者にエスカレーション)して体制を構築し、障害対応を開始
重要なポイントを一言で言うなら、「とにかく一報する」、これに尽きます。
「これは報告した方が良いのだろうか」
「ちょっとまだ分からないな…もう少し調べようか」
誰しもそういう気持ちがよぎることがあるかと思いますが、ここでの遅れが色んな意味で命取りになることがあります。
(e.g. 被害が拡大する、SLAに引っかかる、障害報告で詰められる)
事象確認を怠っていない限り、オオカミ少年になる心配はありません。
不明点があっても「不明」と明示して報告すればよいです。
一報までの時間
なお、対応のルールを定めているところでは「◯分以内に一報」というルールがあると思います。
総務省が携帯電話などの電気通信事業者の通信障害の対応のガイドラインとして取りまとめをしている 電気通信サービスにおける 障害発生時の周知・広報に関する ガイドライン では、障害発生から初報までの時間の目安を原則30分以内としています。
サービスの種類によってここで定める時間には差が出ると思いますが、30分はかなり短いです。
一度障害対応を体験すると分かりますが、ちょっと迷ってしまったら30分はあっという間です。
初動を早めるために必要なこと
だからこそ、障害対応の際に迷わず一報できるよう、以下のようなことを予め決めておくとスムーズです。
- 障害の定義
- どうなったら障害と認識するか
- この定義が曖昧だとエスカレーションの迷いに繋がる
- 実際にユーザ影響がなくても影響の可能性があれば障害とする方が迷いや認識齟齬が少ない
- エスカレーションフロー
- 誰が誰に、どのルートで連絡するか
- 連絡がつかなかったらどうするか
- 別の連絡手段
- 別の or 更に上位のエスカレーション先
- 一報を上げる際に必要な情報の整理
- 障害対象(画面、機能、インフラ構成)
- 発生時刻
- 現在の対応状況
- 障害レベル(緊急度 × 重要度)も定義されている場合は付加すると、より伝わりやすい
- エスカレーションする気満々でも、何を伝えたらよいのか考えてしまうことがあるので必要な項目をテンプレ化しておくと悩まずに済む
(余談)一報するのも必死
「これはヤバい…!」と思って今すぐ作業が必要な状況では一報するのも正直ものすごい負荷が高い、面倒くさい作業です。
私はかつてあるシステム内で使っているクラウドのアクセスキーが漏れたと判明したときに、サービス障害が発生するのを承知で今すぐ無効化するという選択をした経験がありますが、その後の障害報告で一報せず先に作業したことをかなり問題視されました。
この時は、つながるか分からない連絡をしたり、そのシステムを担当しているわけではない上司に時間かけて説明している場合じゃないと考えていたと思います。
ここまででなくても、一報するのが面倒だと処置が遅れる要因になることがあるので、如何に迷わず、素早く上げられるような仕組みになっているかが重要だと認識したケースです。
2. 対策本部の設置
誰が何をするのかはその場の流れで決まることも多いので、何となくそのまま進めて、窓口担当が情報を拾って発信する…という進め方をついしがちです。
対応しているメンバーが同じチーム内の2,3名だけならそれでもなんとかなりますが、それ以上の場合、特に複数チームに渡って調査・復旧対応を進めている場合、対応状況・影響範囲などの把握度合いに格差が生じ、以下のような思い込みによる行動に繋がってしまいます。
- 各自思い思いに作業進めてしまう
- 次に何をすれば良いか分からず手を止めてしまう
- 勝手に終わったと思って帰ってしまう
これらの事象を防ぐために、障害対応を開始する時点で必ず対面(リモートならオンラインMTG)で対応メンバーが一堂に会することが重要です。いわゆる災害対策本部です。
このとき、障害状況を表すダッシュボードとして、ホワイトボードや共有ドキュメントなどで作成します。この事故対策本部としての集まりとダッシュボードにより以下の効果が得られます。
- 誰が何をやるのかが明確になる
- 状況を一元的に整理して認識に差異が生まれるのを防ぐ
- 事故対策本部を進捗報告場所として、勝手な作業をしたり、作業しっぱなしになるのを防ぐ
対策本部にはいつ集まればよいか?
障害対応の作業開始は正式には一報を上げてからになりますが、実際にはアラートを受けて既に対応をしているという状況がほとんどだと思いますので手を止めて集まるというのがなかなか難しいと思います。
ただ、原因調査・影響調査・復旧作業を行うのに手分けをすることが多いので、そのタイミングで集まる(全員その場にいることを確認してアサインを決める)のがよいかと思います。
まず応急処置が必要なケース、特にセキュリティインシデントなどによりNWを遮断するなど、すぐに手を打たないと被害が致命的に拡大するような事象の場合は、応急処置が済んでからでも良いと思います。
そして、手分けして作業を始めたあと、数時間毎など時間を定めて集まります。このとき、必ずそれぞれが行った作業結果を確認して同期をとるのが重要です。
3. 情報発信の一元化
例えば営業経由で複数のお客様からの問い合わせがある一方で、サポートへの問い合わせがあったり、経営陣からのリクエストで上長から情報をよこせと作業者に直接リクエストが入ったりすることがあります。
これらに個別に対応していくのは情報の錯綜や現場の混乱を生むので、障害を検知した以降は窓口(インシデントコマンダー、顧客担当)に一元化しましょう。
4. 報告タイミングと内容に迷ったら
障害対応している方はどんどん時間が過ぎていってしまう感覚がありますが、逆に復旧を待っている方はとても長く感じます。何も報告がないままの時間が続くと、「今どうなってるの?」「まだ直らないの?」と気になって仕方ありません。
そのため、状況に変化・更新があったときは必ず報告すること、さらに30分毎など時間を決めて定期的に状況報告するのが大事です。
また、窓口担当から社内ステークホルダーへの情報発信は、情報格差や連絡漏れを防ぐため、ブロードキャストするのが賢明です。
定期状況報告で気をつけたいこと
- 目立った進捗がなくても報告する
- 報告がないと不安が募るのと、逆に期待を持たせてしまう
- 報告がないと「どうなった?」と個別に問い合わせが入り窓口の負荷が上がる
- 長い空白の時間ができると、後の障害報告でもつらい目に合う
- 対応の進行状況を事実ベースで伝える
- 最も伝えるべき情報は、影響範囲
- 分かったこと、わかっていないこと
- 対応進捗はできたこと、まだできていないこと、今やろうとしていること
- 最も伝えるべき情報は、影響範囲
- 原因は二の次
- 復旧対応を行う上では必要な情報だが、この時点でユーザが欲しい情報ではない
5. 対応を時系列に時刻付きで記録しておく
障害対応の中で行っている作業は、実施内容と結果はもちろん、いつ行ったかを時刻ベースで記録するのが重要です。
これは影響範囲の割り出しの際の条件になったり、のちのポストモーテムや障害報告書で必ず必要になってきます。
また、復旧作業で問題が起きた際の手がかりにもなります。
できれば障害状況のダッシュボード(後述)に記録しておくと後の整理がし易いですが、最低限、Slackに逐一やることをつぶやきながら進めると時刻付きで残るので、おすすめです。
社内のステークホルダーが全員参加しているような障害報告用のSlackチャネルなどを用意しておけば、そちらに書き込めばブロードキャストされるので、対応状況のリアルタイム報告としても機能します。
6. 調査に必要なログは最初に確保する
原因・影響調査を行うには当然、システムのログが必要になってきますが、システムのポリシーによってはログの保存期間が短いことがあります。
障害内容によっては原因・影響調査が数日、数週間など長引くことがあるので、いつでも参照できるものと思ってたら削除・アーカイブされてしまったということは普通に起こり得ます。
調査に必要と思われるログは、調査開始のタイミングで消えないように少し広範囲に保存しておくようにしましょう。
7. 終息宣言を忘れない
復旧したこと、ユーザに復旧連絡できたことなどに安心して意外とやりがちですが、終息を明言しないと、復旧を直接知らない関係者が帰れない、社外ステークホルダーに報告できないなどのトラブルを招くことになります。
いつ、何をもって終息したのか、緊急体制を解除するならその旨を伝えましょう。
まとめ
いかがだったでしょうか。
システム障害対応のノウハウが実践的にまとめられた書籍・記事は少なく、「システム障害対応の教科書」は大変参考になりました。
本当はさらに障害対応の訓練を現場で行うところまでやってようやく、冒頭に書いた「訓練できていない」という状態の根本的な解消になるのですが、最低限のことを押さえていれば、何も分からず焦る気持ちも軽減すると思います。
書籍には今回まとめた内容以外にも「あ、これもチームに伝えたい!」と思える重要なポイントがたくさんありました。興味を持たれた方は是非書籍もご覧いただければと思います。
余談ですが、この本は以前一度借りて読んだことがあるのですが、改めて必要になってから開いてみると全然密度が違いました。
そういう意味では、最初に読む時は頭の片隅に存在を覚えておくだけでも価値があるなと感じます。
この記事は書籍あっての二次的なものではありますが、素晴らしいサービスの裏側で日々運用に奮闘されている皆さまの現場で少しでもお役に立てば幸いです。
We are hiring!
みらい翻訳では、私たちと一緒に開発現場を支えていっていただけるエンジニアを募集しています! ご興味のある方は、ぜひ下記リンクよりご応募・お問い合わせをお待ちしております。