
こんにちは。Mirai Translator 開発チームEMのchika (@chika-mirai) です。
今日はデータレイクについて投稿しようと思います。(初歩的な話題です)
はじめに
Mirai Translator開発チームでは、「5分だけ勉強会」というエンジニアメンバーの勉強会を毎朝開催しています。(以下のWantedlyの記事参照)
毎日開催に感謝!「5分だけ勉強会」を振り返りました | カルチャーを知る
登壇者は参加者全員の持ち回りなので、定期的なアウトプットの習慣づけとして良い刺激となっていますが、公開OKな一般的な話題を扱うことも多いので、できるだけこの「5分だけ勉強会」で話した内容をもとに技術ブログにも投稿していきたいと思います。
今回は、データ分析基盤(データ基盤)と呼ばれるものは何なのかということと、その中心的存在になるデータレイクについて、データ分析基盤の中での役割・位置付けがわかるようになることを目的に、データレイクの初歩的な内容をまとめました。
※実践的な内容ではないので、データ分析基盤に関わっている人には物足りないかと思います。
データ分析とは
やや遠回りになりますが、データレイクの前にデータ分析について書いておきます。 プロダクト・サービス開発の文脈で一口に「データ分析」といっても、その言葉の意味する範囲は広いです。
- マーケティング(顧客分析、需要予測)
- 売上・コスト分析、予測
- サービスの利用状況の可視化
- システム運用状況の監視
などなど、それぞれ関わる人も違うので、頭の中の「データ分析」の定義が十人十色なわけです。
つまり人によってデータ分析の目的が違うので、「データ分析をしたい」といった場合には、何のためにデータ分析をするのかという点は明確にしておく必要があります。
データはどこにあるのか
データ分析の目的を明確にしておく理由の1つとして、目的によって扱うデータとその在処が全く異なるということがあります。
分析に使うであろうデータはあらゆるところに点在しています。
e.g.
- 顧客データ、売上はSalesForceなどのSFA
- サービス利用状況(履歴)はRDBMS
- アクセスログはWebサーバのOSファイル
- アプリケーションのログはBEサーバのOSファイル(そもそも出力されていないかも)
- システムのパフォーマンスデータは監視サーバ / サービス
それぞれ単体での分析であれば、そのシステム内でUIを作って可視化すれば良いですが、複数のデータを掛け合わせて分析したい場合はそれぞれのシステムからデータを収集して一箇所に集める必要があります。
データ分析ニーズは多岐にわたるため、使えそうなデータはすべて収集・保管してしまえばよい、と言いたいところですが、各データが保存されているシステムが別々ということは、管理している部門・担当者も異なるということなので、データ収集するところから難易度が高く、時間・工数がかかるため、優先順位をつけないと大変です。
データ分析基盤とは
では、データ分析基盤とは何でしょうか。
先程書いたデータ分析の目的に沿って、 データの収集・蓄積・加工・分析という一連の流れを一貫して行い、データを利活用するための基盤 であり、この一連の流れを実現するシステムがデータ分析基盤と言えます。
データ分析基盤の構築は、システムごとに行うのではなく、社内(もしくは大きな事業部門内)で一つに集約できるように構築するのが一般的です。
理由の1つは、先程触れたように複数のデータを一箇所に集める必要性があるからです。複数プロダクトを跨いでの分析も企業活動の中では重要になってきます。
(例:CRM分析, O2Oマーケティング, etc)
もう1つの理由として、そもそもデータ分析基盤は構築コストもランニングコストもかなり高くつくので、各システム別や部門別に構築するのは予算的に無駄が多くなってしまいます。
データ分析基盤=DWH?
データ分析基盤と聞いてデータウェアハウス(DWH)を思い浮かべる人も多いのではないでしょうか。
以下、データウェアハウスの概念 より抜粋
データウェアハウスは、より多くの情報に基づく意思決定を行うための、分析可能な情報のセントラルリポジトリです。データは、通常一定の周期で、トランザクションシステム、リレーショナルデータベース、その他のソースからデータウェアハウスに移されます。ビジネスアナリスト、データエンジニア、データサイエンティスト、および意思決定者は、ビジネスインテリジェンス (BI) ツール、SQL クライアント、その他の分析アプリケーションを通してそのデータにアクセスします。
大雑把に特徴をまとめると以下のようになります。
- SQLベースのDB(RDBMSの形式を取っていることが多い)
- 数100GB〜TB級の大量のデータを時系列データとして取り込む
- 分析するデータは大元のデータソースから抽出、読み込み、変換(ELT / ETL)の処理を通して準備する
- 用途を見越して変換(加工)されたデータを保存する
- BIツールとセットで使うのが普通
使い方としては、SQLを直接叩いてアドホックな分析をしたり、定常的に確認するクエリをBIツール上のダッシュボードに可視化して日常的に眺めたりする感じです。
DWHの利用イメージ
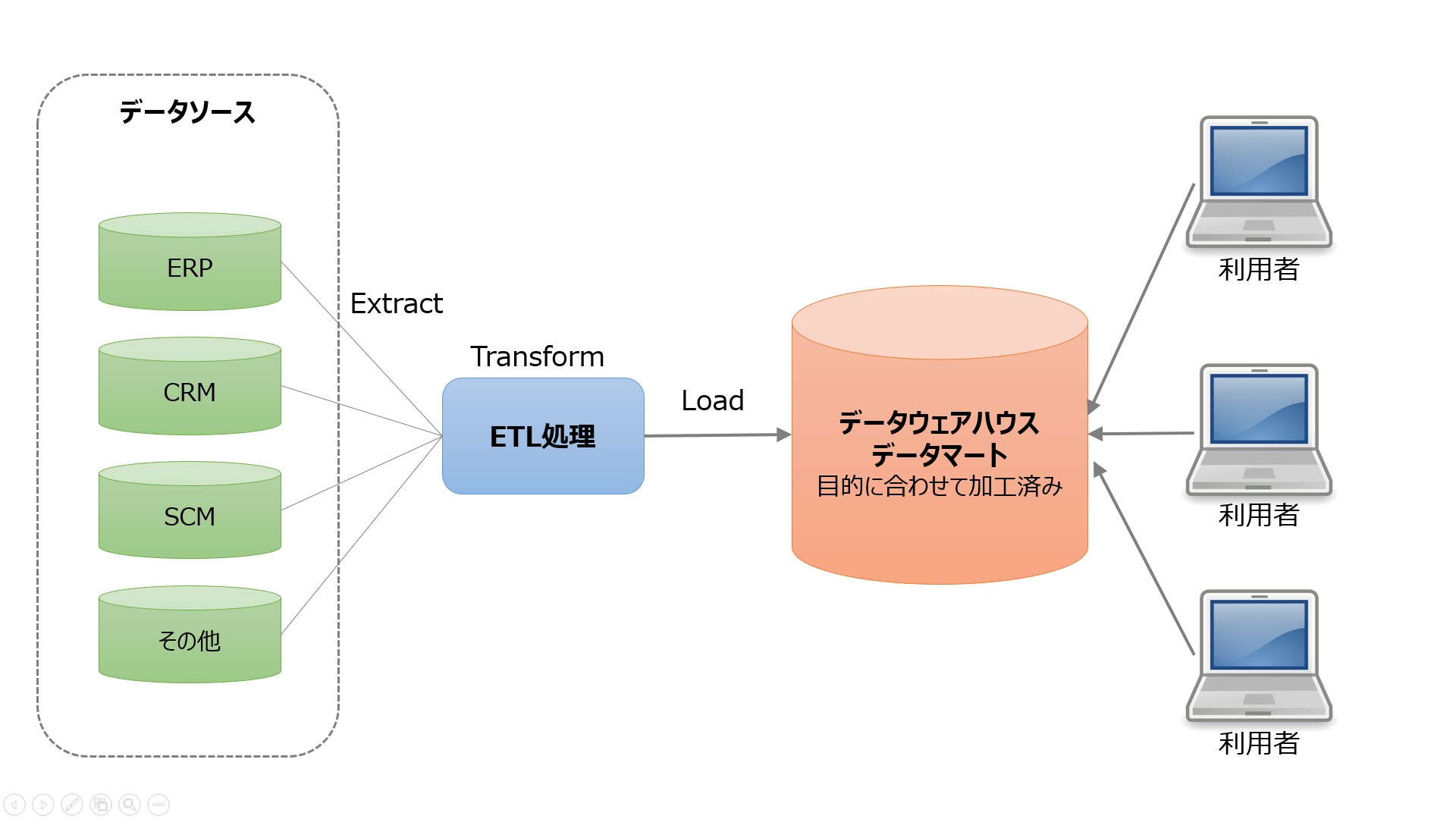
(出典:Think IT データレイクとストリームデータ処理を理解する)
DWHの製品 / サービス
DWHは概念でもありますが、一般的には具体的な製品やサービスを指すことが多いです。
クラウド全盛の現代におけるDWHの代表的なサービスとしてはAmazon RedShift, Google BigQueryなどのデータベースサービスが該当します。
オンプレ環境にはDWHは無かったのかというとそんなことはなく、2000年代後半〜2010年代前半を中心に Oracle Exadata, IBM PureData (Netezza), Cloudera, Teradata などのアプライアンス製品がしのぎを削っており、ビッグデータの盛り上がりとともに存在感を増した印象があります。
これらアプライアンス製品のDWHは、1ラック丸ごとの筐体にブレードサーバ、DISK、スイッチなどがギッシリと収まったシステム一式であり、NW含めてカリッカリにチューニングされたモンスターBOXとなっています。
私もオンプレDWHアプライアンスを使ったことがありますが、数億レコードのテーブルのフルスキャンをINDEXも貼らずに数秒で実行してしまう性能はそれまでのRDBMSの感覚では考えられないほどの衝撃でした。 BigQueryが出てきてからはその衝撃も忘れそうなほどに霞んでしまいましたが、当時は「あぁ、性能は金やハードで解決できるんだ」と実感したのを覚えています。
DWHの課題
この利用イメージを見ると、DWHはデータ分析基盤として特に問題なさそうに思えます。
しかし、DWHのみでデータ分析をしようとするといくつかの問題にぶつかります。
データ増加に伴うストレージのコスト・拡張性
扱うデータ量はあっという間に増えます。構築時に「これだけあれば2,3年は大丈夫だろう」と思っていても、数ヶ月で使い切ってしまってどうしよう、というのはDWHあるあるな気がします。 結果的に古いデータを消すしかなく、思ったよりも長い期間データを保持できません。 ストレージの増加についてはクラウドであれば追加作業自体は容易ですが、決して安くはありません。 オンプレのDWHアプライアンスの場合は拡張する=追加購入なのでそもそも難しいケースが多く、できたとしても大変時間がかかります。
データ形式の制限
DWHがRDBMSベースであるため、連携してくるデータも基本的にRDBMSからのものが多くなります。 もちろん、ログファイルや他システムから提供されたデータファイルなども取り込み可能ですが、RDBMSのテーブルにロードするために加工が必要になります。CSV、TSVならまだ加工しやすいですが、JSONやXMLのような半構造化データをロードするにはそれなりに工数がかかりますし、画像・音声・Officeファイルなどの非構造化データはDWHへの保存は向いていません。
目的指向のデータベースであること
DWHにロードするには構造化データに加工する必要あること、また、ストレージにある程度の制限があることなどから、先のフローイメージでも示されているように、分析対象のデータは事前に必要なフィールドを決めて抽出するなど、目的を持って設計する必要があります。
とはいえ、分析のニーズはどんどん変わっていくので、事前にカチッと設計するのは難しいです。 現時点ではどんな分析をしたらよいかが決まっておらず、アドホックな分析を繰り返すことで見えてくるものもあります。 昨日までいらないと思っていたフィールドが急に必要になることもありますので、「どの項目が必要か?」という事前の要件定義は実情に合わないことが多いです。

(参考資料:【初級】AWS でのデータ収集、分析、そして機械学習 (AWS Summit Tokyo 2019資料))
他システム影響
DWHにつながっているシステムやデータ種類が多ければ多いほど依存性は上がります。 例えばDWHのDBバージョンを上げる、新しい技術基盤に乗り換えるなどでDWHを止めると、連携している各システムは無事でしょうか? 技術の進化も速いので、データを集約する部分に関してもなるべく疎結合な仕組みにしておきたいところです。
データレイク登場
先に挙げたようなDWHの課題を解決する仕組みとして、データレイクという概念が登場します。
以下、データレイクとは より抜粋
データレイクは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリです。データをそのままの形で保存できるため、データを構造化しておく必要がありません。また、ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができます。
データレイクは、データ分析フローの中でDWHの前面に立って、先に上げた課題を吸収する役割を果たします。一方、DWHも不要になるわけではなく、データレイクに蓄積した後、分析層に取り出して加工した構造化データを格納する場所として使用することになります。
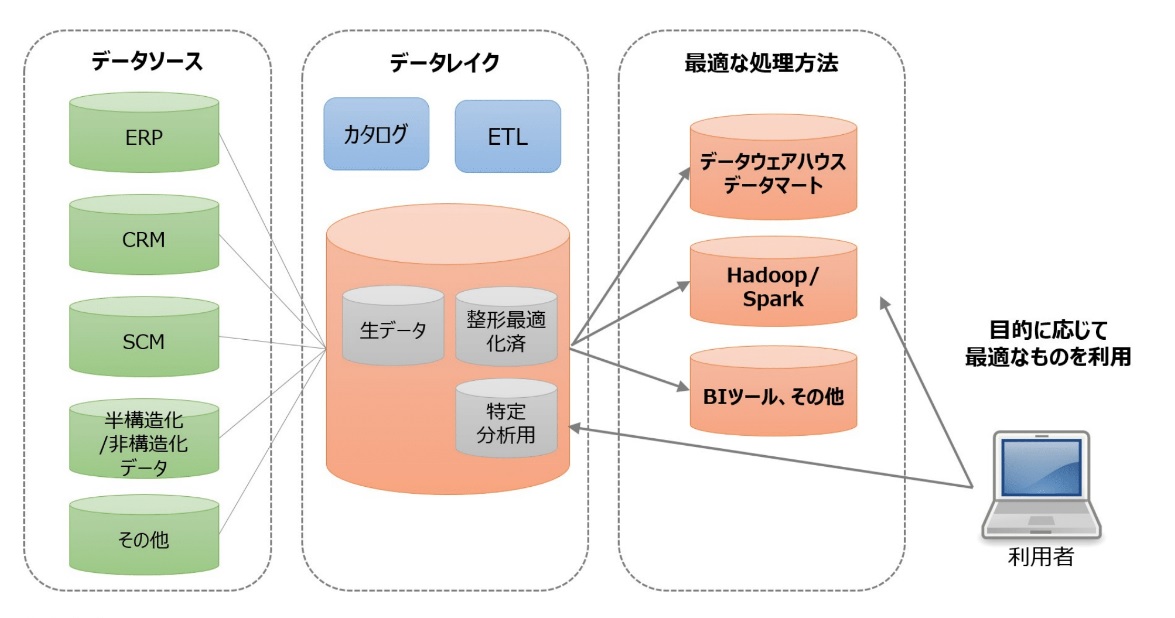
(出典:Think IT データレイクとストリームデータ処理を理解する)
データレイクの要件
データレイクには以下のような機能が求められます。
- 構造化/非構造化を問わない多様なデータを加工せず生で(ローデータで)一元的に保存しておけること
- 処理系と蓄積が分離されていること
- 決められた方法でアクセスできる(≒APIを使って読み書きできる)こと
- これによりデータソース、及び分析環境との結合度を下げることが可能
- データを失わないこと
- サイズ制限から解放されること
これらの要件を踏まえるとDWHような構造化DBでは上記を満たすのは難しく、S3のようなクラウドデータストレージが必要であることが分かります。
(データを消失させることなく無制限に保存できる仕組みを自前で構築出来るわけがない...)
データレイクにより得られる効果
データレイクがあることで、どんなメリットが得られるでしょうか。 先程挙げたDWHの課題を解決することと合わせて整理すると、こんなところでしょうか。
- 収集時に細かい要件定義が不要
- 分析ニーズが新たに出た際に収集・保存部分の改修が不要
- ストレージ側の障害でデータ保管出来ないことによるトラブルの発生確率が限りなく低い
- 大量に蓄積したデータをもとに分析することが出来る
- アドホック(探索的)な分析がしやすい
データカタログ
データレイクを構築・運用する際の重要なポイントとして「データカタログ」があります。
データカタログとは、データレイクに溜まったデータの情報(メタデータ)をまとめてカタログにしたもので、これがあることによって、どんなデータが溜まっているかが把握しやすくなります。
逆にデータカタログがないと、どんなデータが溜まっているかが分からず、せっかく使えるデータでもゴミとなってしまいます。 (このような状態を、DataLake との対比で "Data Swamp" (データの沼地)と呼ぶそうです)
今回はこれ以上深堀りはしませんが、データカタログを作成・管理する仕組みについてもクラウド事業者が提供しているので(AWSの場合、AWS Glue とAWS Lake Formation)、積極的に活用して整備するようにしましょう。
まとめ
- データ分析と一言に言っても、それが指してる分析の目的・内容・必要なデータなどは多様であると認識すること
- データ分析の目的はどんどん変化したり、追加されること
- データ分析のために何かとデータ収集、可視化しようとする際には、それぞれニーズごとに完結させてしまったり、従来からあるDWHなどのデータベースを用いるだけでなく、データレイクを中心としたデータ分析基盤を通して作るのが重要
...というのが伝われば満足です。
参考文献
【初級】AWSで構築するデータレイク 基盤概要とアーキテクチャ例のご紹介(AWS Summit Tokyo 2019資料)
- 【初級】AWS でのデータ収集、分析、そして機械学習(AWS Summit Tokyo 2019資料)
- データレイクアーキテクチャと Purpose-build な分析サービス活用事例の紹介
- データレイクとストリームデータ処理を理解する
みらい翻訳では、一緒に開発を進めてくれるエンジニアを募集しています!
ご興味のある方は、ぜひ下記リンクよりご応募・お問い合わせをお待ちしております。