みらい翻訳の西山です。社内ではlisaと呼ばれてます。機械翻訳エンジン研究開発チームのエンジニアリングマネージャーをしています。
さて、突然ですが、みなさんディープラーニングしてますか?ご自宅にGPUはありますか?
筆者も週末に趣味で文書を分類したりしているのですが、家にあるGPUはNVIDIA GeForce RTX 2080Tiで、バッチサイズを小さくする必要があったりと、少々物足りません*1。
そこで頼りにしたいのがAmazon EC2等の仮想コンピューティング環境ですが、GPUが利用できるサーバーインスタンスは一般に高額で、「必要な時に起動&用が済んだら直ちに終了」を徹底しないと利用金額がかさみがちです。
今日は趣味でディープラーニングをおやりになっている皆様向けに、なるべく安価に構築・運用可能なクラウドディープラーニング環境のご紹介をしたいと思います。
※この記事の内容はみらい翻訳内の研究開発で利用しているコンピューティング環境や、利用ライブラリ等とはまったく関係ありません。また、お試しになる場合には自己責任で利用料金を確認しながら実施してください。
目次
- TL;DR(一言でまとめると)
- 「GPUが必要な時」はいつか?
- 今回提案するシステム構成
- データと処理の流れ
- おわり…と思ったら17ドルの請求が発生していた件
- おわりに: We are hiring!
TL;DR(一言でまとめると)
SageMaker SDKを使って、学習と推論の時だけAWS上のリソースを使うPythonコードを書くと、EC2等のサーバー環境上で試行錯誤しながらコードを書く場合よりも安価にディープラーニングができます。
ただし、推論エンドポイントはServerless Inferenceを利用するか、またはエンドポイントが必要な時に起動&用が済んだら直ちに終了を徹底しないと、EC2を同じ時間立ち上げっぱなしにした場合と同等の料金がかかります。
「GPUが必要な時」はいつか?
さて、「必要な時に起動&用が済んだら直ちに終了」と書きましたが、ディープラーニングのコードを動かす際に、GPUが必要となるのはいつでしょうか?
まず、筆者も含めて多くの方は以下のような流れでディープラーニングのコードを書いたり動かしたりしていると思います*2:
- 考えたり調べたりしながらコードを書く(準備)
- データを学習・評価用に分割したり単語分割等の処理を行う(前処理)
- モデルを学習する(学習)
- 学習済みモデルの精度評価を行う(定量評価)
- 学習済みモデルにいくつかの例を入力してみて、結果を眺める(定性評価)
この中で一般にGPUが必要となるのは3~5の場面で、1~2は時間がかかるものの、GPUの無いコンピューティング環境で済む作業です。また、3~5の評価も、評価結果を得るためにはGPUを利用してモデルの推論処理を行う必要がありますが、得られた評価結果を吟味している間はGPU不要ですよね。
例えばEC2上に環境を作り、そこにssh接続して上記1~5を実施する、というのは非常に簡単な環境構築方法ではあるものの、1で試行錯誤している間や、5で評価結果を吟味している間まで1~数USドル/時間の料金がかかるのは…ちょっともったいない*3。また、インスタンス起動・終了のような操作は、人間が注意深く実施するのではなく、なるべく適切なタイミングに自動で行われるようにしたいものです。
今回提案するシステム構成
そこでこの記事では以下を実現する環境を紹介します:
もちろん同じ環境はEC2を工夫して使うことでも再現できるのですが、ここではSageMakerと周辺サービスを利用して、ローカル環境とAWS環境をより意識せずに使い分けられる開発環境を作ります。
SageMakerを利用することのコスト面以外のメリットとして、学習ジョブの状況をマネジメントコンソール上から確認できたり、任意の学習済みモデルを数クリックまたは数行のコードでAPIとしてデプロイできたりする、といった点も挙げられます。
ご参考までに、AIベンダーのシナモン社が同様の問題意識に基づいてSageMakerをAI開発に導入し、コストを60%ほど削減された事例についてAWS Summit 2019で発表されています(資料,動画)。
構成図は以下の通りです。この後、順を追ってデータと処理の流れを説明します。
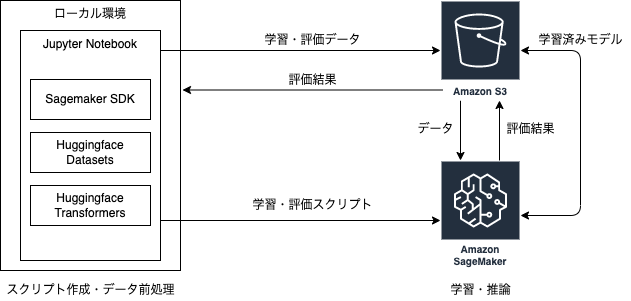
データと処理の流れ
以降は下記のチュートリアル記事の内容に従って進めます(一部コードを修正しています): huggingface.co
扱うタスクと手法
このチュートリアルでは、IMDbというサイトに投稿された英語の映画レビューテキスト25,000件を学習データとして、入力された文章が高評価 (positive) と低評価 (negative) のどちらを示しているか自動判別する、文書分類モデルを学習します。
文書分類モデルを得るにあたっては、DistilBERTという、BERTを軽量化・高速化した事前学習済モデルを用意し、これを上記の学習データでファインチューニング(追加学習)します。この記事ではモデルや学習方法の詳細は割愛しますが、興味のある方はこちらの記事等をご覧ください(日本語版を作られた方もいらっしゃるんですね)。
なお、この記事で紹介する開発環境は、文書分類やDistilBERTに限らず、他のタスク・他のモデルでも利用可能です*4。
ローカル環境にインストールするPythonライブラリ
まずローカルにPython環境を作成し(筆者は3.9を利用)、下記のライブラリをインストールしてください*5:
!pip install "sagemaker>=2.48.0" "transformers==4.12.3" "datasets[s3]==1.18.3" --upgrade !pip install torch --upgrade
これらのライブラリを簡単に説明すると以下の通りです:
- sagemaker: SageMaker Python SDK。PythonコードからSageMakerを操作するためのライブラリ
- transformers: Hugging Face社がOSS提供している、Transformer系の各種事前学習済モデルを利用して、文書分類や機械翻訳、その他自然言語処理タスク向けのモデルを学習するためのライブラリ*6
- datasets: 同じくHugging Face社が提供している、各種公開データセットを機械学習に容易に利用・共有するためのライブラリ
- torch: ディープラーニングフレームワークとしておなじみのPyTorch。transformersの内部で使われています*7。
ローカル環境からSageMakerやS3を操作するためのIAMロールを取得
こちらのガイドに従って、AmagonSageMakerFullAccessをattachしたIAMロールをあらかじめ作成し(下記ではsagemaker-local)、notebookの中でそのロールを取得します。
import boto3 role_name = "sagemaker-local" iam = boto3.client("iam") role = iam.get_role(RoleName=role_name)["Role"]["Arn"]
ローカル環境上でデータセットの取得と前処理
IMDbデータセットをdatasetsライブラリ経由で取得し、transformersライブラリのtokenizerを利用して単語分割を行います。
from datasets import load_dataset from transformers import AutoTokenizer # 後で利用する事前学習済モデル(distilbert-base-uncased)が利用しているtokenizerを指定 tokenizer_name = "distilbert-base-uncased" # IMDbデータセットを指定 dataset_name = "imdb" # データセットを取得して、ランダムに学習・評価データに分割 train_dataset, test_dataset = load_dataset(dataset_name, split=["train", "test"]) # 評価データは25,000件のうち10,000件のみを利用 test_dataset = test_dataset.shuffle().select( range(10000) ) # tokenizerを取得 tokenizer = AutoTokenizer.from_pretrained(tokenizer_name) def tokenize(batch): return tokenizer(batch["text"], padding="max_length", truncation=True) # データセットを単語分割(tokenize) train_dataset = train_dataset.map(tokenize, batched=True) test_dataset = test_dataset.map(tokenize, batched=True) # 単語分割されたデータセットをpytorch用のフォーマットに変換 train_dataset = train_dataset.rename_column("label", "labels") train_dataset.set_format("torch", columns=["input_ids", "attention_mask", "labels"]) test_dataset = test_dataset.rename_column("label", "labels") test_dataset.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
前処理済みのデータのS3アップロード
datasetsのS3拡張を利用して、前処理済みの学習・評価データをS3にアップロードします。
import sagemaker from datasets.filesystems import S3FileSystem sess = sagemaker.Session() s3 = S3FileSystem() s3_prefix = "samples/datasets/imdb" # 学習・評価データをs3://sagemaker-{リージョン名}-{アカウントID}/samples/datasets/imdb/{train, test}以下に保存 training_input_path = f"s3://{sess.default_bucket()}/{s3_prefix}/train" train_dataset.save_to_disk(training_input_path, fs=s3) test_input_path = f"s3://{sess.default_bucket()}/{s3_prefix}/test" test_dataset.save_to_disk(test_input_path, fs=s3)
SageMaker上での学習・精度評価実行
今回最も大きなポイントとなる部分です。このコードによって指定されたバージョンのTransformers、Datasets、PyTorch、PythonがインストールされているDockerイメージがSageMaker上で取得され、train.py という学習・評価スクリプトの実行環境として使われます*8。
train.pyはこのスクリプトです。下記の例ではnotebookが置かれているディレクトリの./smhfというサブディレクトリ内に置かれています。このコードによって、./smhfの中身がパッケージ化されてs3://sagemaker-{リージョン名}-{アカウントID}/{トレーニングジョブ名}/source/sourcedir.tar.gzに置かれます。
学習・評価スクリプトを実行するマシンイメージとしてml.p3.2xlargeという、1時間あたり5ドルほどの利用料金がかかるものを指定している、なかなかハラハラさせられるチュートリアルコードですが、信じて先に進みます*9。
from sagemaker.huggingface import HuggingFace # ハイパーパラメータや利用するモデルの設定。これらはtrain.pyの実行時引数として渡されます hyperparameters = { "epochs": 1, "train_batch_size": 32, "model_name": "distilbert-base-uncased", } huggingface_estimator = HuggingFace( entry_point="train.py", # 学習・評価スクリプト(下記ディレクトリ内のファイル) source_dir="./smhf", # 上記スクリプトが置かれているディレクトリ instance_type="ml.p3.2xlarge", # 上記スクリプトを実行するマシンイメージ instance_count=1, # インスタンス数 role=role, # 前の方で取得したIAMロール transformers_version="4.12", # 実行時のTransformersのバージョン pytorch_version="1.9", # 実行時のPyTorchのバージョン py_version="py38", # 実行時のPythonバージョン hyperparameters=hyperparameters, # 上で指定したパラメータ ) # 学習・評価実行(SageMaker上でトレーニングジョブが作成されます) huggingface_estimator.fit({"train": training_input_path, "test": test_input_path})
学習は15~20分程度で終わり、学習済みモデルがs3://sagemaker-{リージョン名}-{アカウントID}/{トレーニングジョブ名}/output/model.tar.gzに置かれます。
このS3パス含めたトレーニングジョブの結果と詳細は、マネジメントコンソールのSageMaker > トレーニング > トレーニングジョブ > 一覧の中から任意のジョブを選択することで確認できます。学習中のログもここからCloudWatchを辿ることで確認できます。
train.pyはモデルの学習と併せて、評価データを用いた精度評価を実施し、結果をeval_result.txtというテキストファイルに書き出しています。これはs3://sagemaker-{リージョン名}-{アカウントID}/{トレーニングジョブ名}/output/output.tar.gzをローカル環境にダウンロードすることで確認できます。
推論エンドポイントの作成とお試し
せっかく学習したレビュー分類モデルなので、好きな文章を入れて、どんな結果になるか確認してみたいですよね!
下記のコードで学習済みのモデルを推論エンドポイントとしてデプロイすることで、任意の入力での推論結果を確認することができるようになります。
推論エンドポイントにもインスタンスタイプを指定する必要があり、ここでは学習時よりも安価なインスタンスであるml.m5.xlargeを指定しています。
from sagemaker.huggingface.model import HuggingFaceModel model_data = "s3://sagemaker-{リージョン名}-{アカウントID}/{トレーニングジョブ名}/output/model.tar.gz" model = HuggingFaceModel( model_data=model_data, role=role, transformers_version="4.12", pytorch_version="1.9", py_version="py38", ) # ml.m5.xlargeインスタンスを一つ立ててモデルをデプロイ predictor = model.deploy(initial_instance_count=1, instance_type="ml.m5.xlarge")
上記で作成したエンドポイントにリクエストを送るコードは非常に簡単です。下記のsentiment_inputsのように、inputsに処理したい文章を指定したdictを用意し、それをHuggingFacePredictor#predict()の引数とするだけでOKです。
from sagemaker.huggingface.model import HuggingFacePredictor endpoint_name = {作成したエンドポイントの名前} predictor = HuggingFacePredictor( endpoint_name=endpoint_name ) # 推論テスト用の入力(ここでは3つの文章を用意) sentiment_inputs = { "inputs": [ "I love this coffee.", "I never drink this coffee.", "I always drink this coffee.", ] } # 推論エンドポイントにリクエストを送信して結果を得る predictor.predict(sentiment_inputs)
得られた結果は以下です。今回の学習に利用したデータセットではLABEL_1が高評価、LABEL_0が低評価を表していたので、想定通り1番目と3番目の文章が高評価(LABEL_1)、2番目の文章が低評価(LABEL_0)を表している、ということが推定できています。
[{'label': 'LABEL_1', 'score': 0.9879827499389648}, {'label': 'LABEL_0', 'score': 0.8062602877616882}, {'label': 'LABEL_1', 'score': 0.9366642832756042}]
おわり…と思ったら17ドルの請求が発生していた件
さて、チュートリアルの内容も再現できてめでたしめでたし。あとはブログ記事を書くだけ…と思ったところに事件が起こりました。一連のコードを実行した翌日にCost Explorerを確認したところ、謎の請求が上がっていたのです。
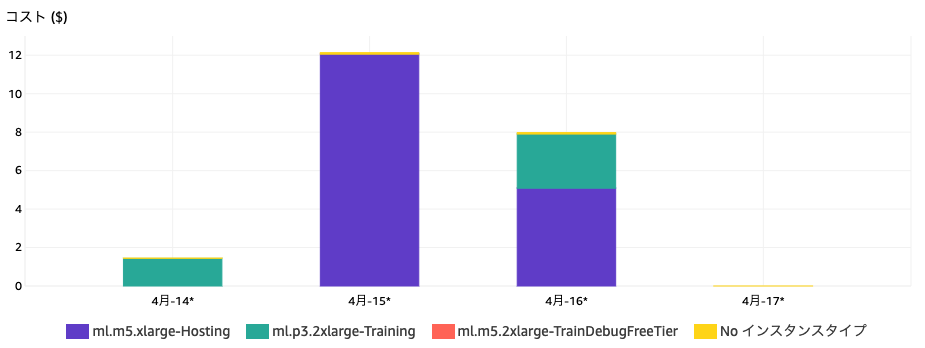
紫のml.m5.xlarge-Hostingは立ち上げた推論エンドポイントのホストインスタンスで、推論エンドポイントを立ち上げている間ずっと利用料金がかかります。筆者は推論エンドポイントをLambdaのようなサーバーレスサービスと勘違いしており、推論処理が走っている時間のみ課金されると思い込んでいたのです。その結果、利用料金をケチる記事のために17ドルの支払いが余計に発生する、というオチとしては最高の結末になってしまいました。
なお、気になる学習用のインスタンス(図中緑のml.p3.2xlarge-Training)の料金は、様々な設定を試すために複数回学習を実行したにも関わらず、合計4.25ドルに抑えられています。このインスタンスは前述のように1時間5ドル程度の利用料金がかかるので、エディタ上で様々な設定を試行錯誤する間も立ち上げていたとしたら、おそらく15~20ドル程はかかっていたと思います。こちらは節約できてよかった、ということで溜飲を下げたいと思います。
推論エンドポイントの削除
上記のようなしくじりを避けるためには、下記のコードで作成したエンドポイントを利用後ただちに削除する必要があります。
from sagemaker.huggingface.model import HuggingFacePredictor predictor = HuggingFacePredictor( endpoint_name={作成したエンドポイントの名前} ) predictor.delete_endpoint()
新しい推論オプション: Serverless Inference
本件を受けて調べたところ、大変喜ばしいことに、この推論エンドポイントをサーバーレスサービスとして立ち上げるオプション(Serverless Inference)が昨年末に発表されたようです。 このオプションを利用することで、Lambdaのように実際のリクエスト処理が行われている間のみ課金される設定になります。 もちろんサーバーレスサービスなので、コールドスタート時のオーバーヘッドはかかると思いますが、用途によっては十分検討可能だと思います。
Serverless Inferenceを利用した推論エンドポイント作成
上の方で説明した推論エンドポイント作成コードを下記のように変更することで、Serverless Inferenceオプションを適用したエンドポイントを作成することが可能です*10 *11。
import sagemaker from sagemaker.huggingface.model import HuggingFaceModel from sagemaker.serverless import ServerlessInferenceConfig model_data = "s3://sagemaker-{リージョン名}-{アカウントID}/{トレーニングジョブ名}/output/model.tar.gz" # 新たに追加。Serverless Inferenceの仕組み上、インスタンスタイプではなく、推論実行用のDockerイメージを指定する必要がある image_uri = sagemaker.image_uris.retrieve( framework="huggingface", region="{リージョン名}", version="4.12", py_version="py38", image_scope='inference', instance_type="ml.m5.xlarge", base_framework_version='pytorch1.9' ) model = HuggingFaceModel( image_uri=image_uri, # 上記で得たImage URIを指定 model_data=model_data, role=role, transformers_version="4.12", pytorch_version="1.9", py_version="py38", ) # あとは下記のようにServerlessInferenceConfigを指定してデプロイすればOK serverless_config = ServerlessInferenceConfig(max_concurrency=1) predictor = model.deploy(serverless_inference_config=serverless_config)
おわりに: We are hiring!
いかがでしたか?筆者はRealtime Inferenceとして作成する推論エンドポイントの削除の必要性と、Serverless Inferenceのありがたみ、そして何よりCost Explorerを監視することの重要性を身をもって体験したわけですが、この記事がご自宅でディープラーニングされる皆様のお役に立てれば幸いです。
当機械翻訳エンジン研究開発チームではリサーチャーを募集しています。併せて、機械翻訳モデルのチューニングを行うエンジニアも募集しています。ご興味をお持ちいただいた方はカジュアル面談も実施しておりますので、下記リンクよりお問い合わせください。
*1:先日アキバでRTX 3090Tiを指くわえて眺めていたりもしたのですが、グラボだけではなく併せてケースと電源の買い替えも必要で、なかなか踏み出せないのですよね。家の電力使用量も気になりますし…(完全に余談です)
*2:もちろんこの手順がストレートに流れるわけではなく、行きつ戻りつすることの方が多いと思います。また、ここで説明しているのはどちらかと言えば研究開発の手順で、本来であればこの後に本番稼働向けのデプロイや監視が入ります。
*3:あくまでケチな筆者の感想です。
*4:ただしtransformersやPyTorch以外の、後述するSageMaker SDKが対応していないフレームワークを使う場合は、独自の学習用Dockerイメージを作ってECRにpushする等の工夫が必要です。
*5:バージョンはチュートリアル記事からリンクされているこのnotebookの記載に従いました。チュートリアル記事では微妙に古いバージョンが指定されているので、少し注意が必要です。
*6:最近はテキストデータだけでなく、画像や音声等にも対応しています。
*7:このチュートリアルではPyTorchを利用していますが、後述の学習・評価スクリプトをTensorFlow2.0対応に改変したりすることでTensorFlow2.0を利用することも可能です。詳しくはこちらのnotebookをご覧ください。
*8:別の言い方をすると、ここで指定する各種ライブラリのバージョンは既にDockerイメージとして用意されている組み合わせに準じている必要があります。Dockerイメージのリストはこちら。
*9:読者の皆様におかれては適宜安価なGPUインスタンスに置き換えていただいて構いません。なお、利用するインスタンスによってはチケットを上げてサービスの利用上限値を変更する必要があるかもしれません。
*10:今年2月4日の時点ではまだSagemaker SDKがServerless Inferenceに対応していなかったようですが、今回利用したv2.84.0では対応されているようです。